AI technology is advancing at lightning speed, and the search for greater efficiency has led to a breakthrough: FP4 quantization. This 4-bit floating-point format, when combined with Lambda’s NVIDIA HGX B200 clusters, is enabling organizations to deploy and scale large AI models with unprecedented speed and cost savings without sacrificing accuracy.
Understanding FP4 Precision
FP4, or 4-bit floating point, encodes numerical values using one sign bit, two exponent bits, and one mantissa bit.
This streamlined structure reduces both memory usage and computational load, making it possible to process data much faster.
For AI practitioners, this means models can be deployed with a smaller memory footprint and lower VRAM consumption, which is essential for large-scale, resource-intensive workloads.
Major Benefits of FP4 for AI
- Reduced Memory Demand: Large language models can shrink dramatically in size such as Qwen3-32B dropping from 64GB to just 24GB.
- Increased Throughput: Converting models from FP16 to FP4 can deliver up to 3x faster inference, a game-changer for applications like the FLUX model.
- Energy Savings: Lower precision means less power is needed, reducing both energy usage and operational costs.
- Enhanced Scalability: More complex models run efficiently, even on hardware with limited resources.
Seamless FP4 Quantization on Lambda’s HGX B200
Transitioning to FP4 is simplified with Lambda’s 1-Click Clusters, which come equipped with pre-installed tools like NVIDIA TensorRT™. Users can employ both Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) to prepare their models.
The workflow, quantizing a Hugging Face GPT-2 model, exporting to ONNX, and optimizing with TensorRT, demonstrates how straightforward it is to deploy FP4-optimized models in Lambda’s high-performance environment.
While FP4 support in the broader NVIDIA software ecosystem remains experimental, Lambda’s hardware provides native support, making it the top choice for innovators eager to maximize efficiency.
Credit: Lambda
Real-World Impact: The FLUX Model Case Study
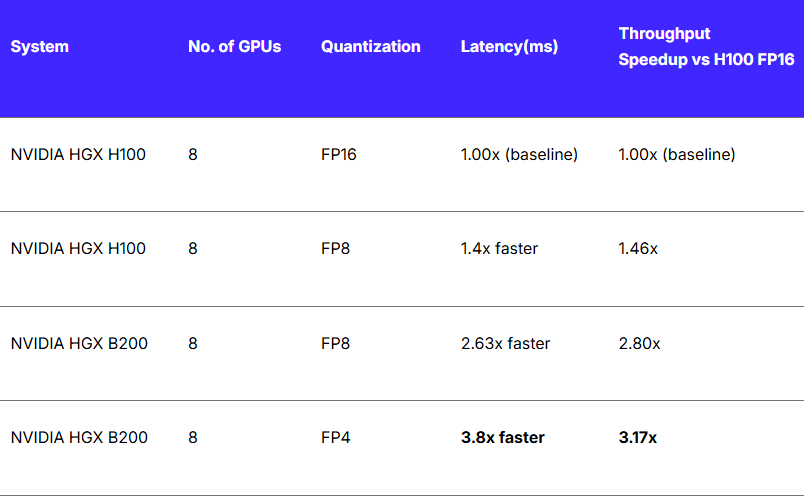
The FLUX transformer model showcases FP4’s benefits. After quantization, FLUX saw VRAM usage drop by about 60% and inference throughput triple compared to FP16, all with no loss in image quality. On Lambda’s NVIDIA HGX B200 clusters, the results were particularly impressive:
- 3x higher throughput versus FP16 on H100 GPUs
- As much as 68% lower latency for interactive apps
- Consistent performance at ultra-low precision even as model complexity rises
- Faster image generation and batch processing, boosting productivity
- Lower total cost of ownership by reducing the need for additional GPUs
Visual benchmarks confirm that FP4 maintains prompt adherence and image quality, making it viable for demanding generative tasks.
Lambda’s FP4-Ready Cloud Platform
Lambda’s cloud services are tailored for FP4 workloads, making it easy to:
- Launch on-demand, multi-node clusters without long-term commitments
- Achieve up to 3x faster training and 15x faster inference
- Scale from 16 to 1,536 GPUs, leveraging high-speed NVIDIA InfiniBand networking
- Benefit from pre-configured environments for rapid AI deployment
FP4 Delivers Near-FP8 Accuracy
Recent testing with NVIDIA’s NVFP4 format and TensorRT shows FP4 can achieve accuracy almost on par with FP8 even for massive models like DeepSeek-R1 and Llama 3.1 405B.
For example, Llama 3.1 405B reached over 13,800 tokens per second at 96.1% accuracy; DeepSeek-R1-0528 achieved more than 43,000 tokens/sec at 98.1% accuracy sometimes even exceeding FP8 results.
Unlocking the Future of Scalable AI
FP4 quantization, especially when harnessed through Lambda’s NVIDIA HGX B200 clusters, represents a turning point for AI efficiency and scalability. With impressive boosts in speed, memory efficiency, and cost-effectiveness, plus minimal impact on accuracy, FP4 is ready for widespread adoption by forward-thinking AI teams. Lambda’s robust cloud infrastructure ensures these benefits are accessible now, empowering organizations to lead the next wave of AI innovation.


FP4 Quantization Meets NVIDIA HGX B200: A New Era of Efficient AI