As artificial intelligence systems become central to search, support, and communication, their ability to deliver consistently accurate information is under intense scrutiny. Google DeepMind’s FACTS Benchmark Suite steps up to this challenge, offering a robust framework to assess and enhance the factual reliability of large language models (LLMs) in practical applications.
Inside the FACTS Benchmark Suite
FACTS is a collaborative effort between DeepMind and Kaggle, designed to push the boundaries of factual assessment in AI. It introduces a comprehensive set of four benchmarks that each target a specific facet of factual reasoning:
- Parametric Benchmark: Gauges how well a model can answer knowledge-based questions using only its pre-trained data with no outside help or tools allowed.
- Search Benchmark: Evaluates a model’s ability to search for, retrieve, and weave together information from the web to solve multi-step queries.
- Multimodal Benchmark: Measures factual accuracy in answering questions about images, testing both visual processing and textual knowledge integration.
- Grounding Benchmark v2: Focuses on how well a model justifies its answers using the specific context provided in the prompt.
With 3,513 rigorously selected examples and both public and private test sets, FACTS ensures unbiased and meaningful scoring. Kaggle’s management brings transparency, with a public leaderboard tracking the performance of leading LLMs.
How Each Benchmark Works
Parametric Benchmark: This test dives into a model’s internal knowledge base, using trivia and fact-based prompts that reflect real-world reference queries.
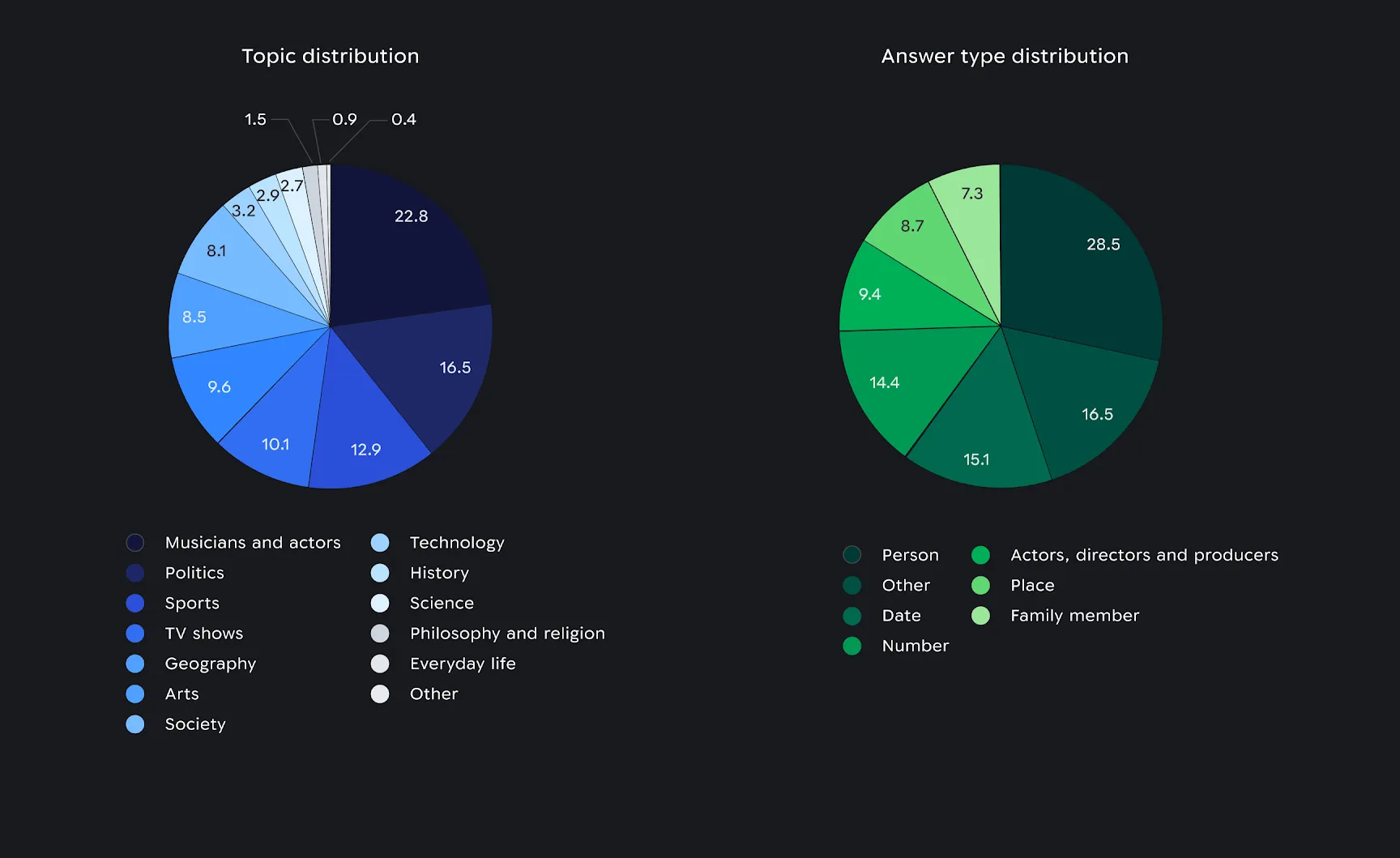
Distribution of context domain (left) and distribution of the answer type (right) as a percent of the total set of questions in the Parametric benchmark.
Search Benchmark: Unlike the purely knowledge-driven test, this challenge requires active online research and synthesis, simulating how users expect modern AI to operate.
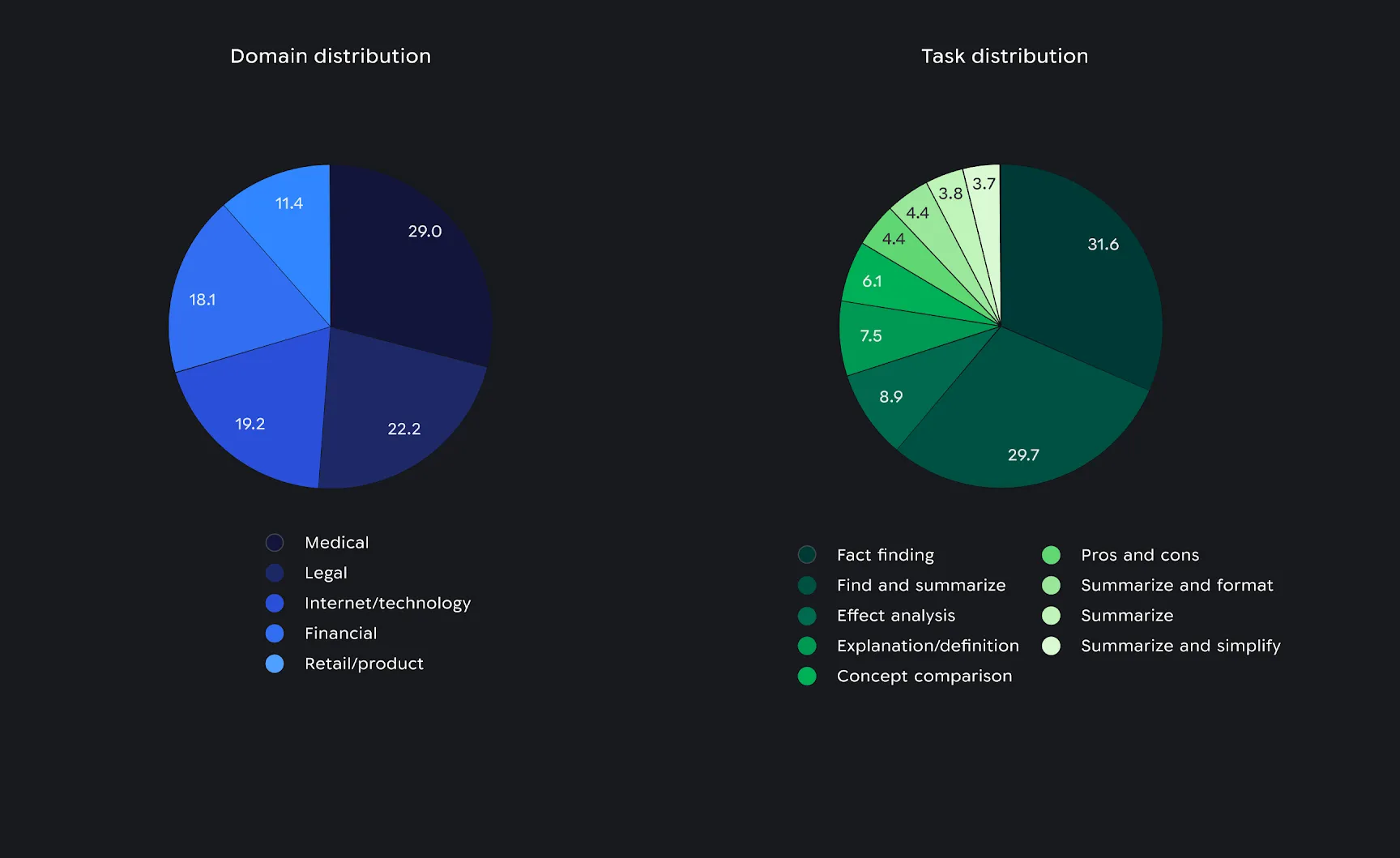
Distribution of context domain (left) and distribution of the task requested by the user (right) as a percent of the total set of prompts in the Search benchmark.
Multimodal Benchmark: As AI expands into image understanding, this benchmark assesses a model’s ability to accurately interpret and respond to questions based on pictures.
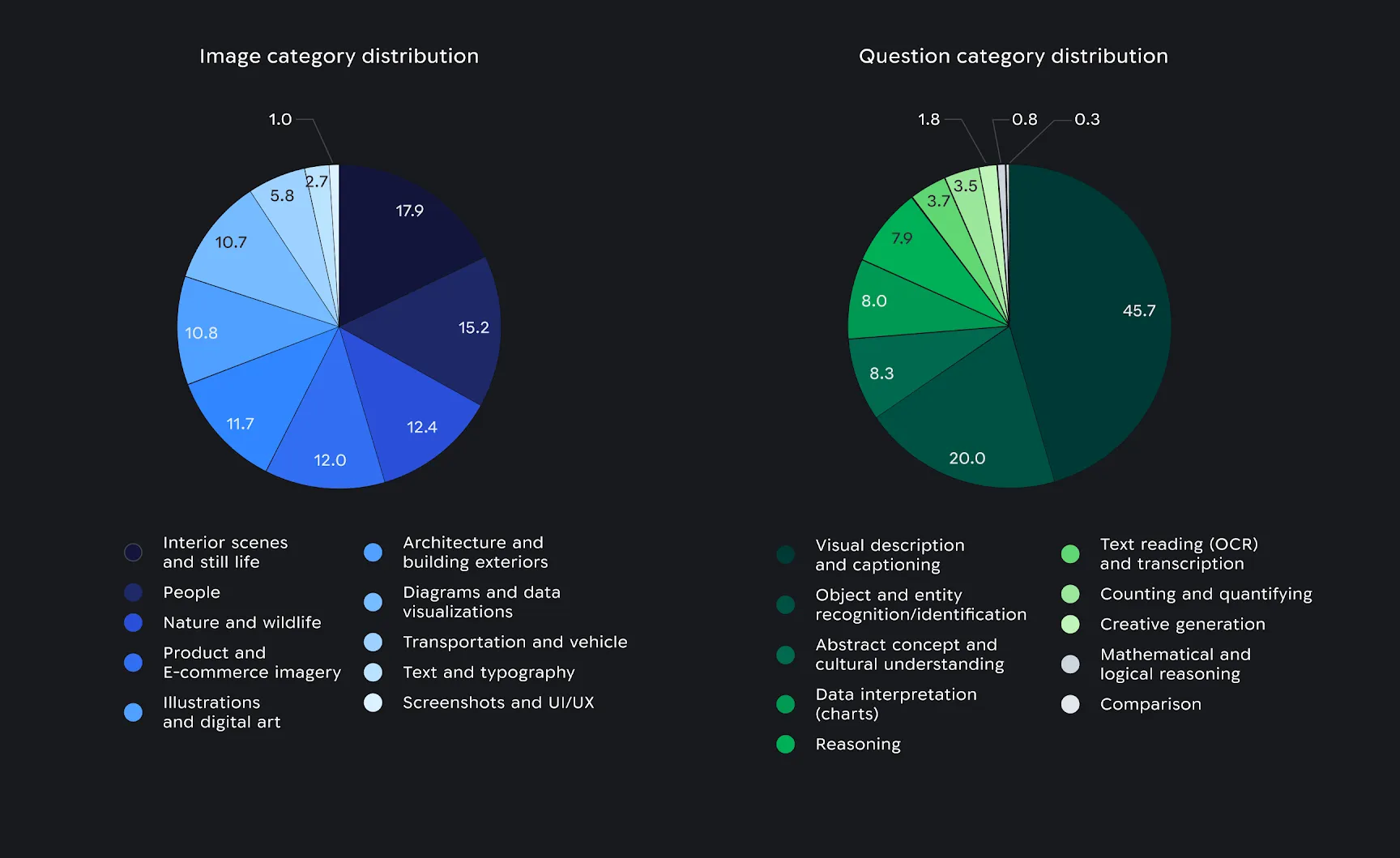
Distribution of image (left) and distribution of the question categories (right) as a part of the Multimodal benchmark.
Grounding Benchmark v2: This advanced test measures whether a model’s answers are anchored in the information provided, ensuring context-aware accuracy.
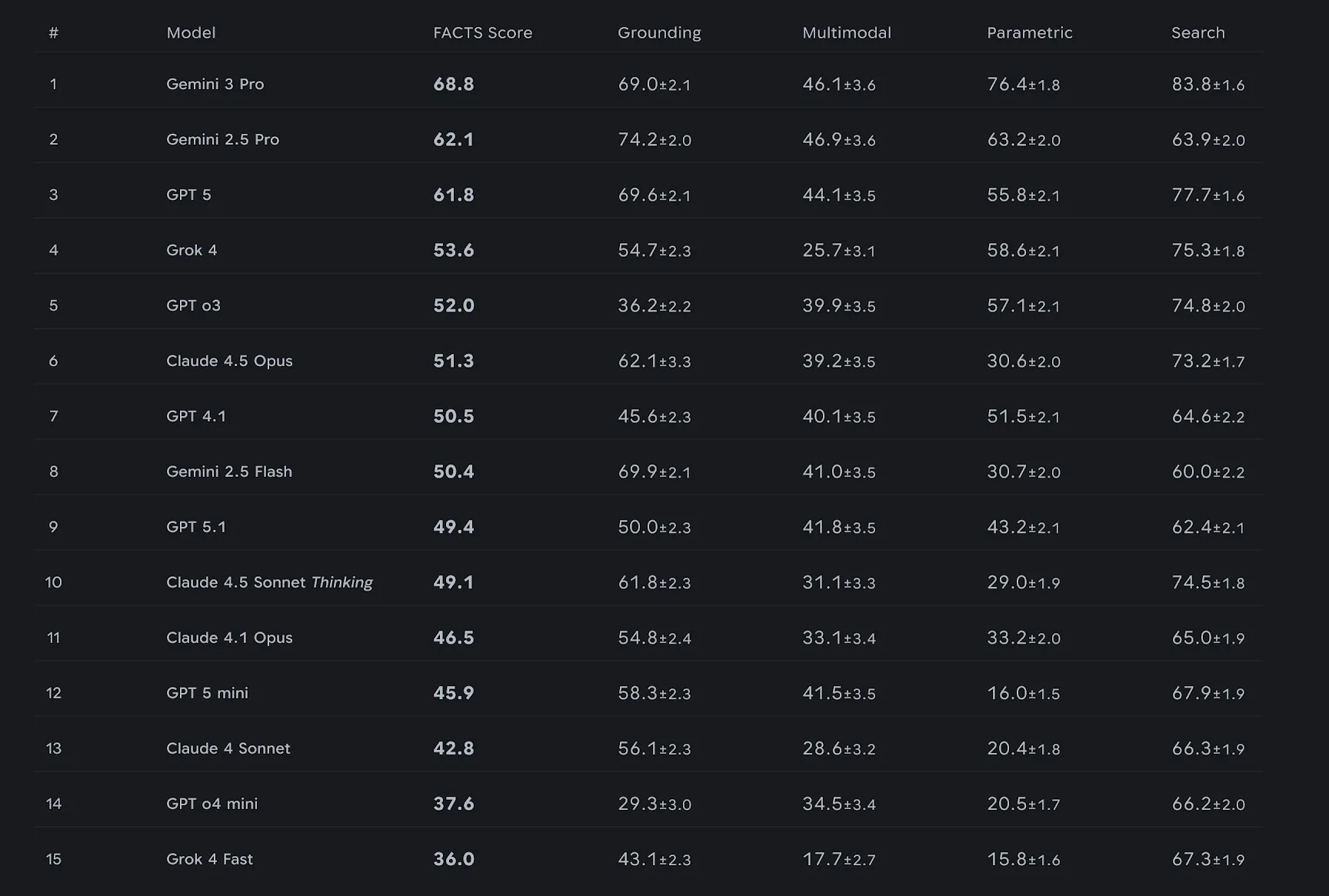
Benchmarking Results: Leaders and Lessons
Fifteen top LLMs were evaluated on the FACTS Suite. Gemini 3 Pro led the pack, posting a FACTS Score of 68.8%. Its upgrades over previous versions were notable, achieving a 55% drop in Search error rates and a 35% reduction in Parametric errors.
However, accuracy for all models stayed below 70%, with the Multimodal benchmark proving especially difficult. This gap highlights the nuanced challenges in achieving robust factuality across text and images.
Further validation came through the SimpleQA Verified benchmark, where Gemini 3 Pro significantly outperformed Gemini 2.5 Pro, reinforcing the reliability of FACTS findings.
Understanding the FACTS Grounding Benchmark
FACTS Grounding is an industry-standard benchmark designed to test both factual accuracy and whether responses stay grounded in the referenced documents provided to the model. By setting a higher bar for response quality, DeepMind hopes to foster transparency and healthy competition with a public leaderboard on Kaggle tracks how leading LLMs perform against this standard.
The Dataset: Comprehensive and Diverse
At the heart of FACTS Grounding is a carefully constructed dataset with 1,719 examples. Each entry includes a document, a system instruction emphasizing exclusive reliance on that document, and a user query that demands a detailed, substantive answer. This design pushes LLMs to synthesize information accurately and thoroughly.
- Split for Security: The dataset divides evenly between a public set (860 examples) and a private held-out set (859 examples), minimizing score gaming.
- Wide-Ranging Content: Domains covered span finance, technology, medicine, law, and retail, with document lengths reaching 32,000 tokens.
- Diverse Tasks: User prompts cover summarization, Q&A, and rewriting, while avoiding creativity, mathematics, or advanced reasoning to focus strictly on factual grounding.
Evaluation: How FACTS Grounding Works
Evaluating factuality with consistency is no simple task. FACTS Grounding leverages a unique, automated judging system using three top-tier LLMs: Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet. This multi-judge approach helps reduce bias and increase the reliability of results.
- Two-Stage Judging: First, responses are checked for adequacy, do they fully address the user’s request? Next, judges assess whether the answer remains grounded in the source document with no invented or extraneous material.
- Comprehensive Scoring: Scores from all judges are aggregated, producing an overall grounding score for each model.
- Human Alignment: The automated process is validated against human ratings, confirming its reliability and trustworthiness.
What This Means for the Future of AI
The FACTS Benchmark Suite is more than a scorecard, it’s a catalyst for ongoing research and improvement in LLM factuality. By opening its benchmarks and results, Google DeepMind invites the broader AI community to innovate and collaborate toward more reliable AI systems.
While current results show there is work to be done, tools like FACTS are vital for advancing the trustworthiness of AI. Iterative improvements in both benchmarks and models promise a future where users can trust AI for accurate, context-aware answers, across any domain or modality.
Building Trust in AI, One Benchmark at a Time
FACTS signals a shift toward systematic, transparent evaluation of AI factuality. As benchmarks evolve and technologies improve, the industry moves closer to delivering universally reliable, knowledge-driven AI experiences.
Source: Google DeepMind, "FACTS Benchmark Suite: Systematically evaluating the factuality of large language models" & FACTS Grounding: A new benchmark for evaluating the factuality of large language models


FACTS Benchmark Suite: Setting a New Standard for LLM Factuality