Imagine accessing advanced AI features like semantic search and private chatbots directly on your device with no connection needed. Google DeepMind’s EmbeddingGemma allows just that with a compact and efficient embedding model, uniquely engineered for mobile-first and on-device applications.
Compact Model, Outstanding Performance
At just 308 million parameters, EmbeddingGemma outperforms larger competitors while remaining highly efficient. Built on the Gemma 3 architecture, it stands as the leading open multilingual text embedding model under 500M parameters, based on the Massive Text Embedding Benchmark (MTEB). Its design allows it to run comfortably on less than 200MB of RAM when quantized, supporting devices from smartphones to desktops.
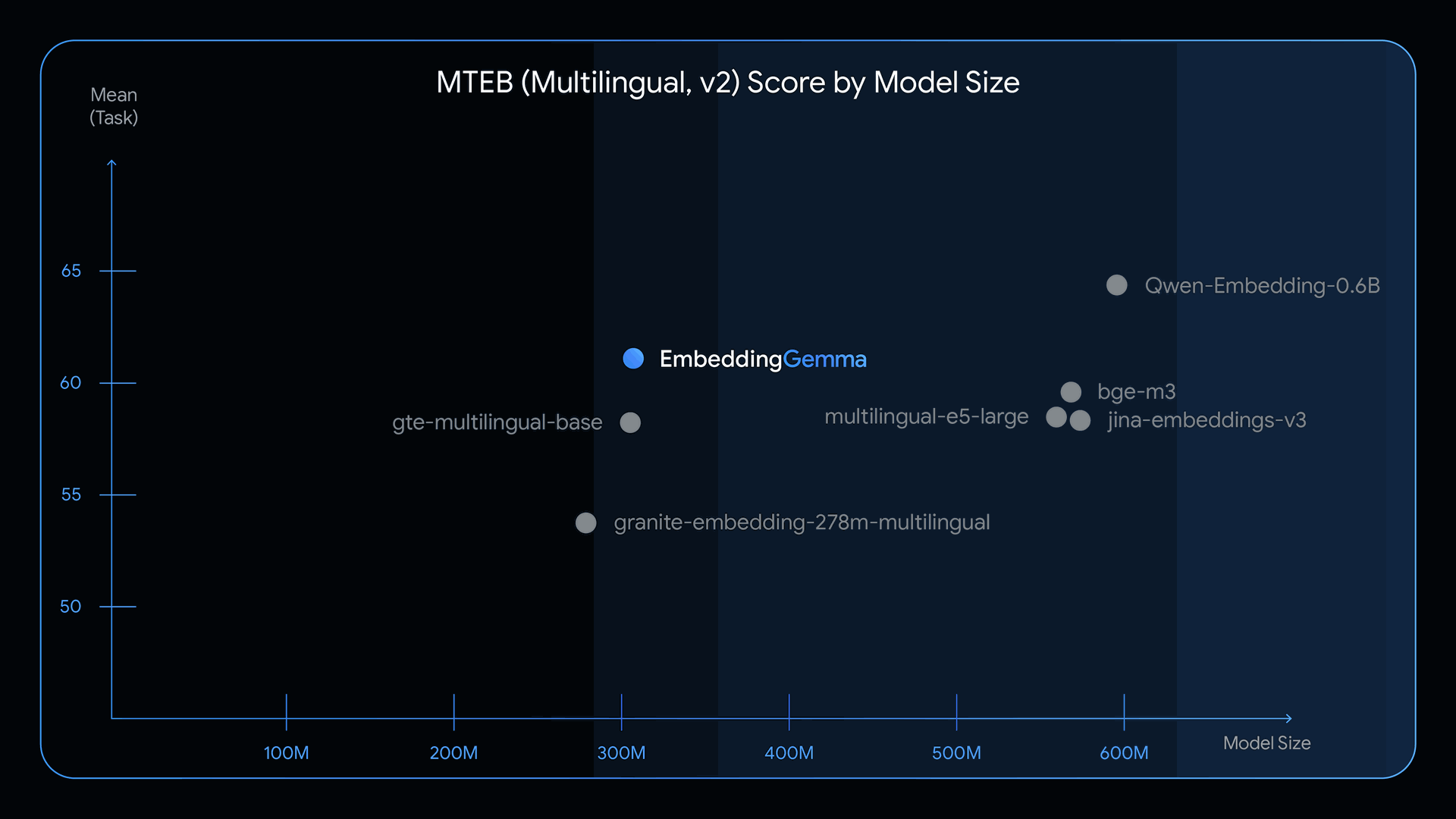
Image Credit: Google
Engineered for Speed, Efficiency, and Privacy
- Flexible Embeddings: Choose vector dimensions (128–768) to prioritize speed or quality.
- Real-Time Performance: Achieves under 15ms embedding inference for 256 tokens on EdgeTPU, ensuring instant feedback.
- Low Resource Use: Quantization-Aware Training (QAT) keeps RAM needs under 200MB while maintaining high quality, perfect for mobile and embedded devices.
- Privacy-First: All computations happen locally, so sensitive data stays on your device.
Flexible, Offline AI at Your Fingertips
EmbeddingGemma’s offline capability is a game changer. Developers can adjust output dimensions (768 to 128) using Matryoshka Representation Learning, balancing quality with resource use for different needs.
The wide 2,000-token context window supports advanced scenarios such as Retrieval Augmented Generation (RAG), semantic search, and document classification right on your device. Integration with tools like sentence-transformers, llama.cpp, MLX, Ollama, and transformers.js makes getting started straightforward.
Optimized for Mobile-First Retrieval
Designed for retrieval-centric workflows, EmbeddingGemma excels in RAG pipelines. It generates high-quality text embeddings that quickly identify and retrieve relevant information based on user queries. When paired with generative models like Gemma 3, it delivers accurate, privacy-first answers, even when connectivity is unreliable.
Multilingual Power and High-Dimensional Support
Despite its size, EmbeddingGemma shines in retrieval, classification, and clustering especially across languages. Its 100 million model parameters and 200 million embedding parameters enable nuanced understanding in more than 100 languages. Performance benchmarks confirm superior accuracy and efficiency over similarly sized models.
Versatile Applications and Easy Fine-Tuning
EmbeddingGemma unlocks a spectrum of privacy-focused AI use cases:
- Searching personal content (texts, emails, or files) without cloud reliance
- Offline, personalized chatbots powered by RAG and Gemma 3
- Automatic, on-device query classification for smarter mobile agents
- Domain-specific or language-specific tuning using quickstart notebooks
An interactive, in-browser demo (using transformers.js) demonstrates real-time visualization of text embeddings, highlighting EmbeddingGemma’s capabilities.
Selecting the Best Embedding Model
For privacy-centric, offline, and on-device applications, Google recommends EmbeddingGemma. For large-scale or server-based deployments, the Gemini Embedding model (via the Gemini API) remains the top choice for ultimate performance.
Getting Started Is Simple
- Download: Access model weights on Hugging Face, Kaggle, and Vertex AI.
- Comprehensive Guides: Documentation covers inference, fine-tuning, and RAG integration.
- Broad Support: Use EmbeddingGemma with platforms like transformers.js, MLX, llama.cpp, LiteRT, Ollama, LMStudio, and Weaviate.
Final Thoughts
EmbeddingGemma sets a new standard for on-device AI, enabling developers to build efficient, multilingual, and privacy-first applications. Whether you’re building mobile search, offline chatbots, or intelligent personal assistants, EmbeddingGemma is ready to elevate your next project.


EmbeddingGemma: Powering Private, On-Device AI Experiences