Enterprises aiming to deploy AI agents tailored to their proprietary data face the challange of delivering high-performance inference that can scale with complex, fragmented workloads.
Parameter-Efficient Fine-Tuning (PEFT) techniques, like Low Rank Adapters (LoRA), offer a compelling solution for memory-efficient customization, but serving these models rapidly and reliably at scale isn't straightforward.
Databricks’ Mosaic Research Team has developed an advanced inference runtime that outshines open-source alternatives, offering both speed and uncompromised quality for PEFT workloads.
The Unique Challenge of Serving PEFT Models
PEFT methods allow organizations to fine-tune models without the heavy costs or inefficiencies of full retraining. However, they introduce technical hurdles during inference, especially as enterprise workloads demand low latency and support for thousands of concurrent, diverse requests. The theoretical efficiencies of PEFT can be negated by practical system bottlenecks, underscoring the need for end-to-end optimization.
Key Innovations Driving Databricks’ Inference Runtime
- Framework-First Optimization: Databricks takes a holistic approach, orchestrating scheduling, memory management, and quantization for maximum throughput, not just focusing on GPU kernel speed.
- Quality-Conscious Quantization: Advanced FP8 quantization is balanced with hybrid formats and fused kernels, delivering acceleration without sacrificing model accuracy.
- Maximizing Overlap: Overlapping kernel and stream scheduling maximizes GPU utilization, a crucial factor for workloads with frequent, small matrix multiplications.
- Minimizing CPU Overheads: Efficient task preparation ensures the GPU remains busy, vital for handling high-volume, small-batch inference requests.
Fast LoRA Serving: Overcoming Bottlenecks
LoRA stands out as the preferred PEFT technique, but its performance can be hampered by the overhead of numerous small matrix operations at inference time. While best practices involve wide application of LoRA adapters and scaling their capacity to data size, open-source solutions often struggle with these fine-grained computations.
- Databricks’ runtime delivers up to 1.5x greater throughput than leading alternatives like vLLM, maintaining model quality.
- Custom GPU kernel partitioning and overlapping eliminate delays typical in LoRA’s matrix multiplications.
- Optimized attention and GEMM implementations ensure accuracy, validated against benchmarks such as HumanEval and Math.
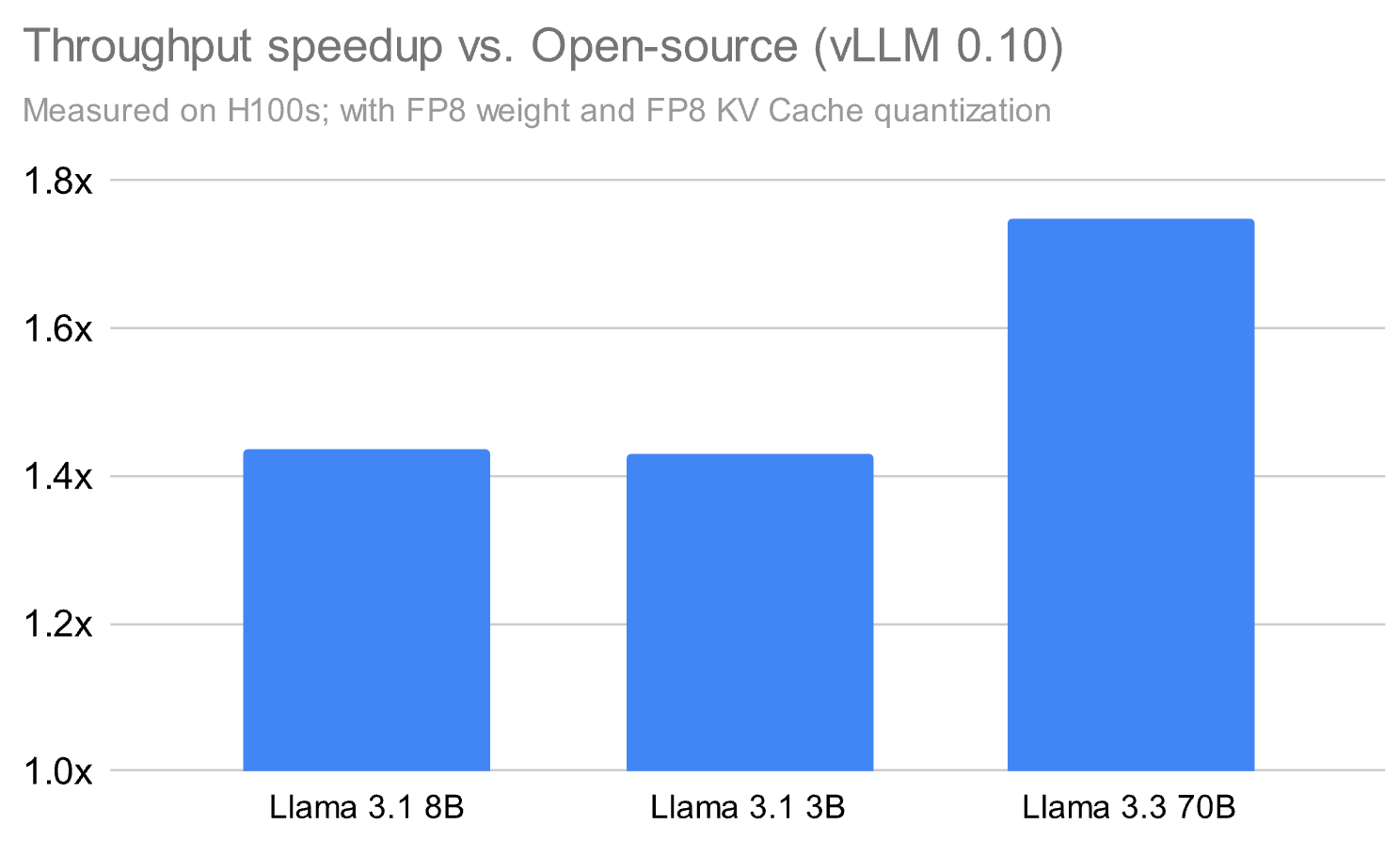
Image Credit: Databricks
Maintaining Quality Through Advanced Quantization
Quantization is a double-edged sword: while it boosts speed, it can degrade accuracy if not handled with care. Databricks’ approach leverages training in native bf16 precision and switches to FP8 for inference, using rowwise scaling and kernel fusion to minimize error. Hybrid attention kernels further blend FP8 and bf16 computations, especially in softmax layers, preserving fidelity while enabling rapid inference.
Advanced GPU Techniques: Fused Transforms and Kernel Overlap
To optimize quantization, Databricks applies fused Fast Hadamard Transforms (FHT) after RoPE embeddings, spreading variance and enabling tighter, more granular FP8 scaling. This approach, inspired by cutting-edge research, allows for enhanced quantization with minimal performance trade-off.
For inference efficiency, the runtime partitions GPU Streaming Multiprocessors (SMs), allowing concurrent execution of base and LoRA computations. Advanced CUDA features, like Programmatic Dependent Launch (PDL), enable even dependent kernel operations to overlap seamlessly, eradicating latency in complex, multi-adapter scenarios.
Reliable, Production-Ready Model Serving
Beyond performance, Databricks’ infrastructure is designed for enterprise reliability: auto-scaling, intelligent load balancing, multi-region deployment, and comprehensive security features come standard. Each optimization is rigorously validated against statistical benchmarks, ensuring that speed never comes at the cost of accuracy.
Organizations can now confidently deploy custom AI agents at scale, leveraging their unique datasets and the latest in serving stack innovation. Looking ahead, Databricks plans to further enhance scheduling intelligence and kernel fusion to set new standards for scalable, high-performance AI inference.
Source: Fast PEFT Serving at Scale by The Mosaic Research Team, Databricks


Databricks Delivers Fast, Scalable PEFT Model Serving for Enterprise AI