Deploying large language models requires balancing accuracy and efficiency, a challenge that intensifies as demand for high-throughput generative AI grows. The open-source gpt-oss model, featuring a mixture-of-experts architecture and a 128K context window, has set new standards for both performance and accessibility. Yet, its native MXFP4 (4-bit floating point) format, while resource-efficient, brings instability and accuracy loss when models are adapted to specific tasks through fine-tuning.
Why Low-Precision Fine-Tuning Is Challenging
Directly fine-tuning gpt-oss in FP4 precision can result in unstable training and subpar performance which is an unacceptable risk for safety-critical or complex applications. To address these issues, NVIDIA introduced a two-step fine-tuning workflow that leverages the strengths of both high and low precision training.
- Supervised Fine-Tuning (SFT) on a higher-precision (BF16 or FP16) upcasted model ensures stable adaptation to new tasks.
- Quantization-Aware Training (QAT) with NVIDIA TensorRT Model Optimizer helps the model regain and even improve accuracy after re-quantizing back to FP4.
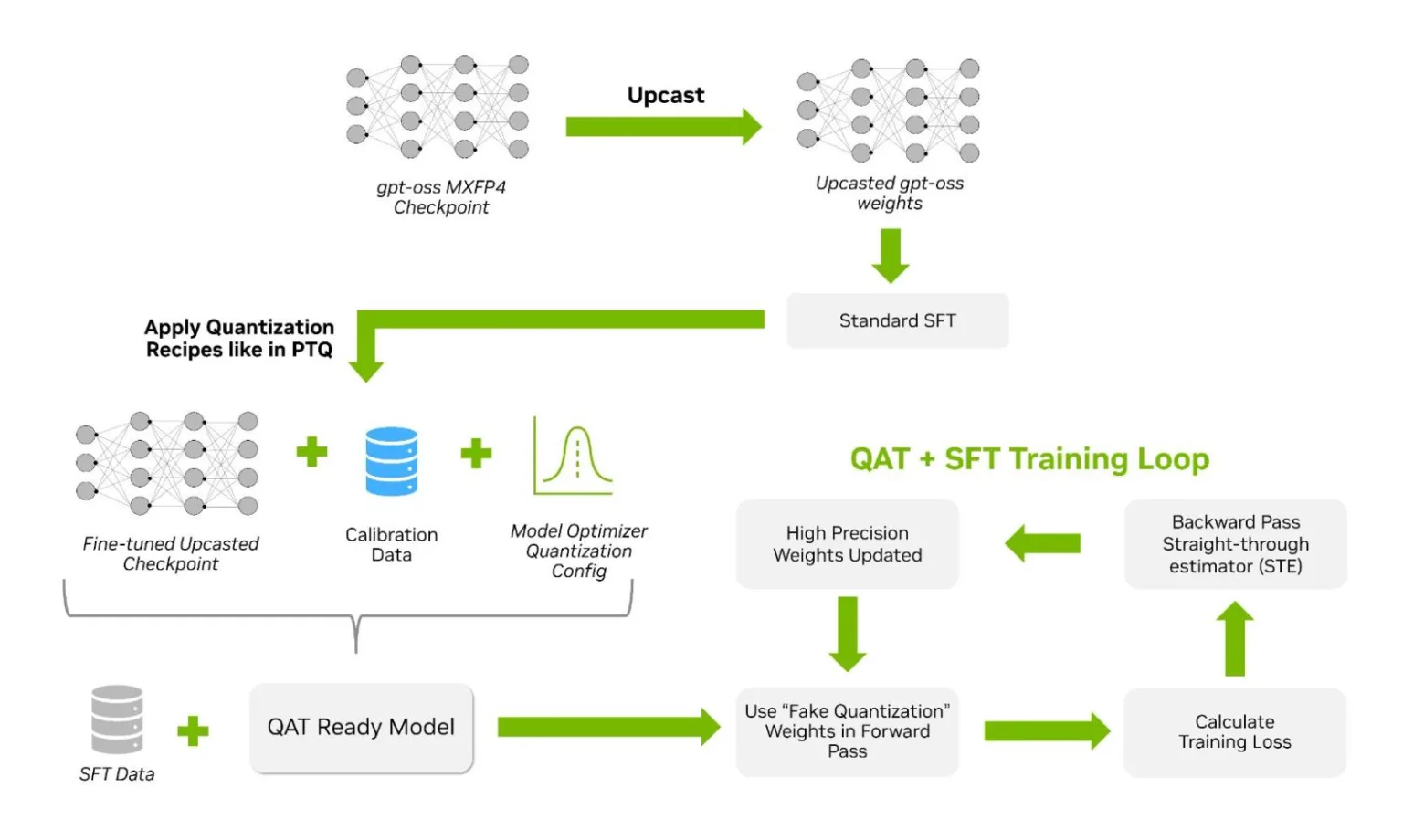
Figure 1. QAT and SFT workflow for gpt-oss: from upcasted checkpoint to quantization-ready model Credit: NVIDIA
Step-by-Step Fine-Tuning Workflow
The recommended process is straightforward for practitioners seeking reliable results:
- Upcast the original MXFP4 checkpoint to BF16 or FP16 using Hugging Face Transformers or similar tools. This step stabilizes gradients and is efficient since fine-tuning uses fewer tokens than pre-training.
- Conduct SFT on your task-specific data, enabling the model to learn without the constraints of quantization.
- Quantize using TensorRT Model Optimizer, preparing the model for QAT or post-training quantization (PTQ).
- Perform QAT at a lower learning rate, allowing the model to adapt its weights for optimal FP4 inference while recovering any lost accuracy.
This workflow consistently outpaces direct QAT from the original FP4 checkpoint, with the SFT + QAT approach delivering strong performance across diverse benchmarks.
Impressive Results Across Key Tasks
Adopting this two-step process for gpt-oss led to substantial improvements:
- Non-English reasoning tasks saw pass rates leap from 16% to 98%.
- Safe prompt acceptance rates soared from 30% to 98%.
These gains underscore the effectiveness of combining SFT and QAT, especially for multilingual and safety-sensitive applications where accuracy is paramount.
Next Generation: NVFP4 and Blackwell Platform
The arrival of NVFP4, a new FP4 format designed for both training and inference on NVIDIA's Blackwell platform, offers even greater accuracy and efficiency. Switching to NVFP4 within this workflow is simple and requires only minor configuration changes.
Early findings show an advantage for demanding use cases and stricter deployment needs with NVFP4-trained models converging faster and achieving 2–3% lower validation loss than those using MXFP4.
Seamless Deployment and Integration
After fine-tuning and QAT, NVIDIA provides scripts to convert checkpoints back to MXFP4 or NVFP4, ready for production using TensorRT-LLM or other open-source inference engines. This ensures smooth integration into existing AI workflows and supports scalable, efficient deployment at any level.
Bridging Reliability and Efficiency
Upcasting to BF16 for SFT, followed by QAT, is the key to unlocking both reliability and low-precision efficiency. This strategy not only restores but often enhances model accuracy, providing the cost and performance benefits essential for real-world AI adoption.
As NVFP4 becomes more widely supported, organizations can expect even tighter convergence and greater flexibility for deploying advanced generative models in production.
Source: NVIDIA Technical Blog


Boosting Low-Precision AI: Fine-Tuning GPT-OSS with Quantization-Aware Training