Developers building large language model (LLM) applications know that getting trustworthy evaluation feedback is critical—but also challenging. Automated scoring systems often misalign with human expectations, causing confusion and wasted iteration. Align Evals by LangChain, now integrated into LangSmith, tackles this problem by giving teams tools to calibrate evaluator prompts and bring automated scores in line with human judgment.
Transforming the Evaluator Development Process
Traditionally, improving LLM-as-a-judge evaluators meant guessing why scores changed and laboriously tweaking prompts without clear feedback. Align Evals changes the game by introducing several features that make evaluation transparent and actionable:
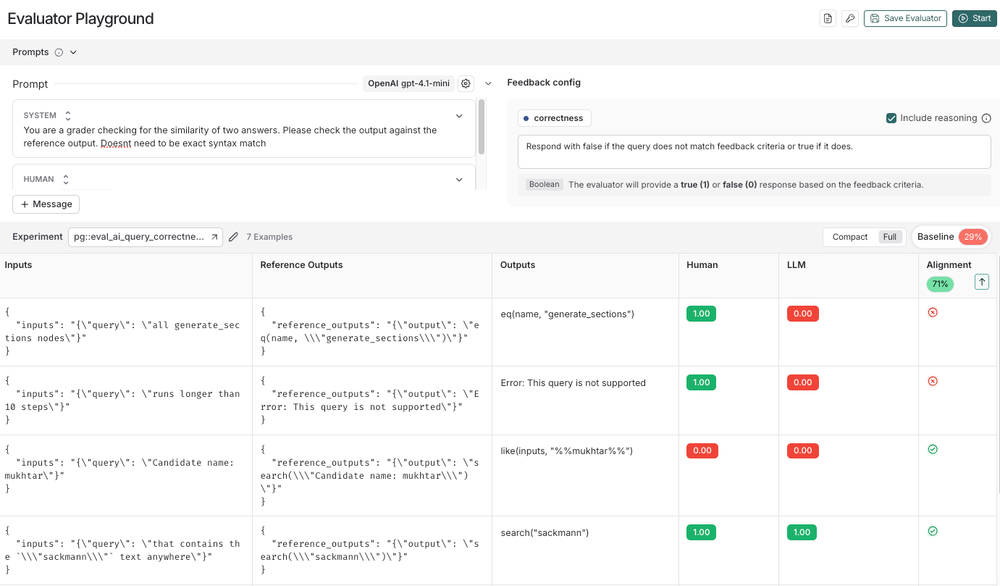
- Interactive playground: Instantly experiment with and adjust evaluator prompts, receiving an "alignment score" to visualize how changes impact agreement with human grades.
- Side-by-side comparison: View human-graded examples and LLM-generated scores together, sorted to help spot where evaluators disagree most.
- Baseline tracking: See how your evaluator’s performance improves (or regresses) as you refine prompts over time.
How to Use Align Evals Effectively
The Align Evals workflow is designed for clarity and repeatability. Here’s how teams can systematically calibrate evaluators:
- Select evaluation criteria: Define what success looks like for your application—such as correctness, conciseness, or relevance.
- Gather representative examples: Assemble a set of real outputs, ensuring coverage of both strong and weak cases.
- Manual grading: Assign human "golden set" scores to each example. These become the benchmark for alignment.
- Prompt iteration: Develop and refine your evaluator prompt, testing each version against the golden set. Analyze mismatches, such as over-scoring irrelevant answers, and update prompts for better alignment.
This cycle helps teams make data-driven improvements, aligning automated evaluations with the subtlety of human perspectives.
Looking Ahead: Analytics and Automatic Optimization
LangChain is planning further enhancements for Align Evals. Soon, teams will gain:
- Analytics: Visualize trends in evaluator accuracy and monitor performance over time.
- Automatic prompt optimization: Let the system generate and test new prompt variations, accelerating the path to a well-aligned evaluator.
These features will make it even easier to trust automated assessments as true reflections of human feedback.
Start Calibrating Today
Align Evals is currently available for LangSmith Cloud users and will roll out to LangSmith Self-Hosted soon. Developers can dive into the documentation and tutorials to get started, and LangChain welcomes community input to keep improving the tool.
A New Era in LLM Evaluation
With Align Evals, LangChain is empowering teams to take control of their evaluation process. By making calibration fast, visual, and human-centric, teams can trust that their automated scores actually represent what users care about most.
Turn Your AI Concepts into Reality
Understanding how to evaluate your LLMs is a crucial step, as we saw with Align Evals. But it’s just one of many steps in building a truly intelligent application. The real journey involves architecting data pipelines, developing custom agents, and integrating these complex systems securely into your existing workflows.
For the past two decades, my focus has been on exactly that: turning cutting-edge concepts into practical, custom software solutions. With significant experience helping businesses design and deploy complex AI and automation, I can help you build the robust, scalable applications you need. If you're ready to move past the documentation and start building, reach out and let's talk.
If you're curious about how my experience can help you, I'd love to schedule a free consultation.



Align Evals: Making LLM Evaluation More Human-Centric and Reliable