If you're an AI developer, you've likely faced the "tool overload" problem. You start with a few tools, and your agent works perfectly. But as you add hundreds more, you watch in real-time as latency increases, costs spiral, and accuracy falls off a cliff. This is a well-documented phenomenon, with some models dropping to just 0-20% accuracy when faced with large tool catalogs.
This article dives into a powerful new solution, the vLLM Semantic Router's semantic tool selection feature, which solves this problem with a reported 99.1% token reduction and a 3.2x improvement in accuracy, fundamentally changing the economics of building with LLMs.

vllm-project
Organization
semantic-router
Intelligent Router for Mixture-of-ModelsThis open-source project, built by the team behind vLLM, represents a fundamental shift in how we think about AI Tool calling. Semantic Router introduces dynamic, context-aware tool routing that automatically directs requests to the most appropriate tool based on semantic understanding of the query, computational requirements, and business constraints. The developers call this "Semantic Tool Selection" and it aims to complement MCP (model context protocol) by offering tool access for large catalogs.
Credit: vLLM
The Tool Overload Crisis
Have you noticed that as the number of available MCP tools grows, performance doesn't improve - it collapses. According to studies cited in the project's comprehensive analysis, when AI agents have access to approximately 50 tools (consuming around 8,000 tokens), most models maintain 84-95% accuracy.
However, when that number scales to over 700 tools (requiring a 100,000+ tokens), accuracy plummets to just 0-20% for most models resulting in a catastrophic degradation that renders systems essentially unusable.
The problem manifests in multiple ways. First, there's the sheer computational overhead of loading hundreds of tool definitions into the context window for every request. This consumes significant tokens, increases latency, raises costs, and may actually reduce accuracy as models face increasingly complex selection decisions.
Second, there's a relevance problem. In most cases, the vast majority of available tools simply aren't relevant for any given query. When a user asks about the weather in San Francisco, they don't need access to database tools, email clients, and calendar APIs - but traditional approaches load them all anyway.
Perhaps most insidious is the "lost in the middle" effect. Research shows that tools positioned in the middle of long lists are systematically less likely to be selected correctly. With 741 tools for example, middle positions showed accuracy rates of just 22-52% compared to 31-32% at the beginning or end positions.
This position bias, combined with non-linear performance degradation as tool counts increase, creates a scenario where adding more capabilities actually makes the system less stable.
Semantic Tool Intelligence: The Answer to Scale
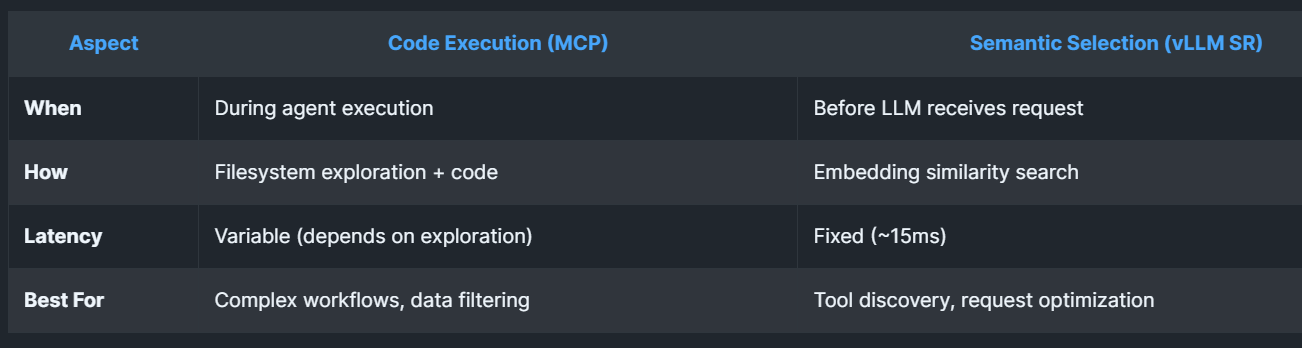
The vLLM Semantic Router approaches this problem with an elegant solution rooted in semantic understanding through the semantic tool selection feature. Rather than loading all available models and tools into every request, the system uses pre-computed embeddings and similarity search to intelligently filter options before the request ever reaches the language model.
"The vLLM Semantic Router implements semantic tool selection as an intelligent filter that sits between the user and the LLM"
This three-stage process - tool database with embeddings, query embedding and similarity search, and request modification - dramatically reduces the computational burden while improving accuracy.
At its core, the router maintains a database where each tool has a rich description optimized for semantic matching, a pre-computed embedding vector, and optional metadata like categories and tags.
When a user query arrives, the system generates an embedding for that query, calculates cosine similarity with all tool embeddings, selects the top-K most relevant tools above a similarity threshold, and then injects only those relevant tools into the actual request sent to the language model.
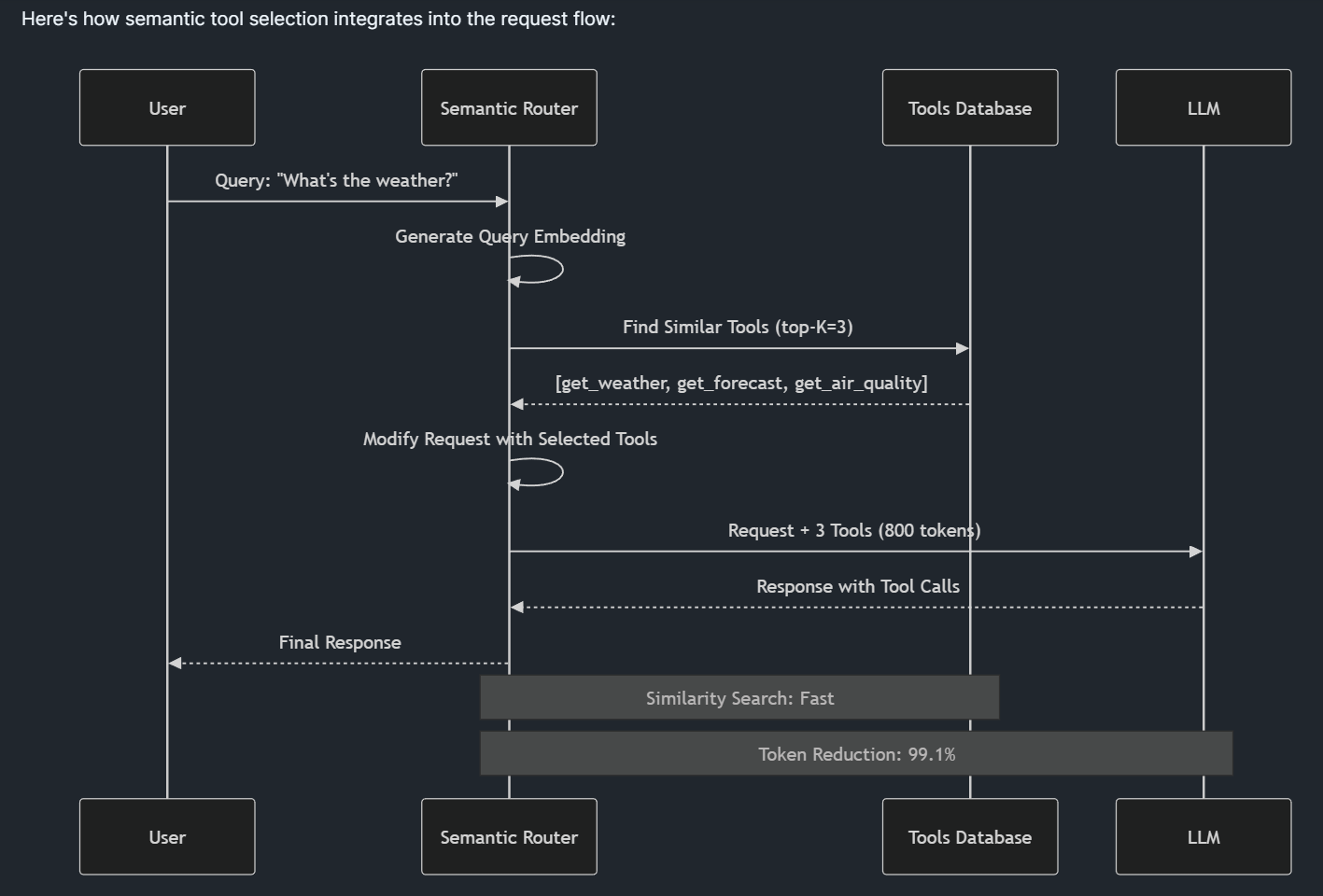
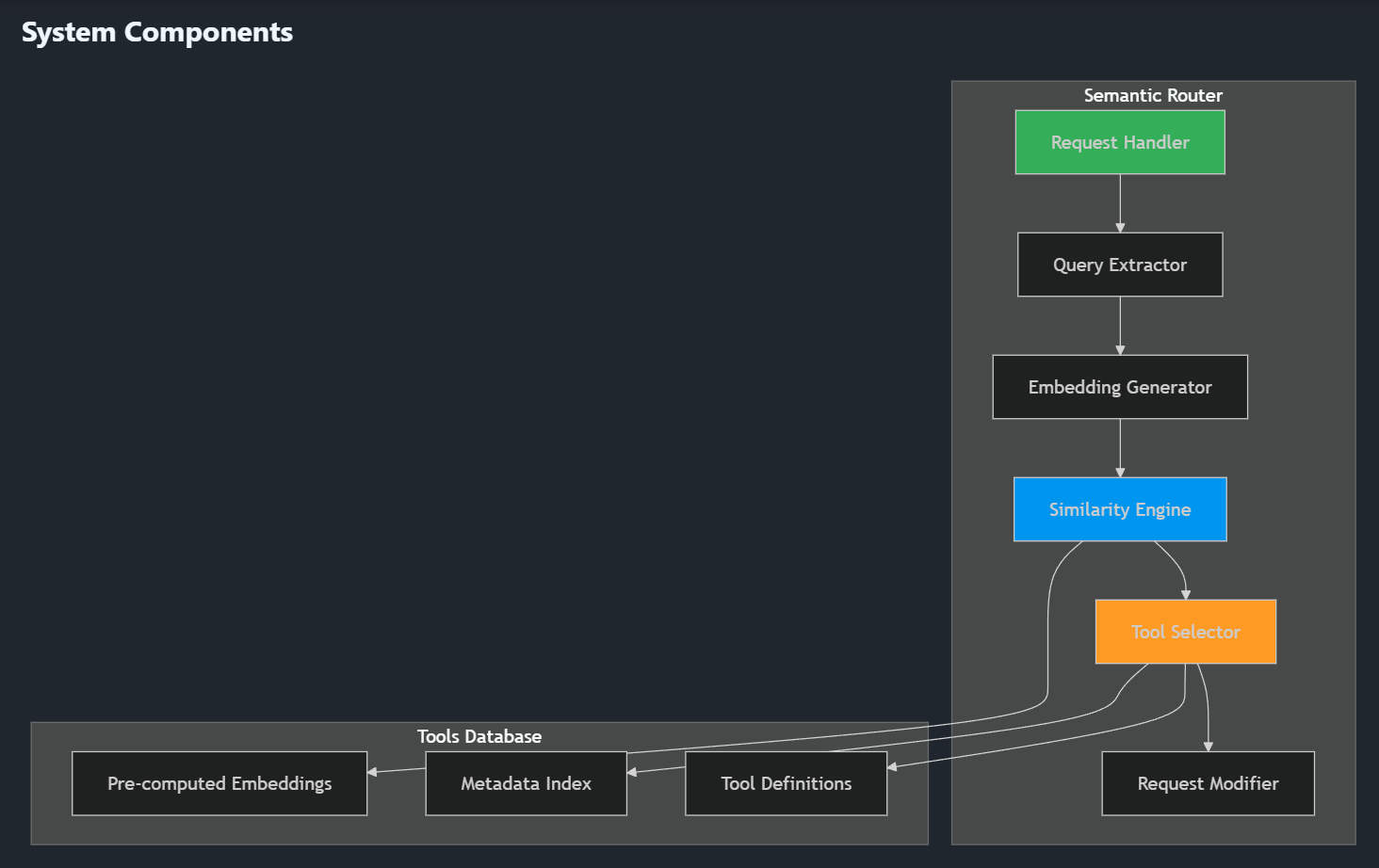
Image Credit: vLLM
The results are pretty impressive with benchmarks like the Berkeley Function Calling Leaderboard dataset, where the Semantic Tool Router achieved 99.1% token reduction (from 127,315 tokens down to just 1,084 tokens) while simultaneously improving accuracy from 13.62% to 43.13% - a 3.2x improvement. Perhaps more importantly, the system eliminates position bias entirely, maintaining consistent 94% accuracy regardless of where tools are positioned in the original catalog.
Why This Solution Resonates
What makes the vLLM Semantic Router particularly compelling is how it addresses multiple pain points simultaneously. The project doesn't just solve a technical problem - it fundamentally rethinks the economics and architecture of AI systems.
By reducing token consumption by over 99%, organizations can slash their inference costs from hundreds of thousands of dollars per year to just thousands. The system potentially saves $194,578 annually for an organization processing just 1 million requests per month with a large tool catalog according to the company.
Beyond cost savings, the main router's approach to intelligent model selection opens up new architectural possibilities. The Mixture-of-Models pattern it Semantic Router enables is conceptually similar to Mixture-of-Experts within a model, but operates at the infrastructure level, selecting entire models based on task requirements.
This means organizations can maintain a heterogeneous fleet of models - some optimized for coding, others for mathematics, still others for creative writing - and automatically route requests to the best match without manual intervention or complex logic.
The project also demonstrates remarkable engineering pragmatism. Rather than requiring a complete infrastructure overhaul, the Semantic Router integrates seamlessly with existing systems through the Envoy proxy External Processing interface.
It supports deployment on Kubernetes, offers comprehensive monitoring through Grafana dashboards, and provides both Go and Python implementations for maximum flexibility. This production-ready approach, combined with thorough documentation and active community support, makes adoption realistic for organizations of any size.
Key Features That Define the System
The vLLM Semantic Router's feature set extends well beyond basic routing. At its foundation is intelligent routing powered by ModernBERT fine-tuned models that understand context, intent, and complexity to direct requests to the most suitable LLM. This isn't simple keyword matching - the system performs deep semantic analysis to truly comprehend what each query requires.
Security features are built into the core architecture with advanced PII detection, it identifies and can mask sensitive information before it reaches models. While prompt guard functionality detects and blocks jailbreak attempts. These aren't afterthoughts bolted onto the system; they're integral components of the routing pipeline that protect organizations without adding significant latency.
The semantic caching system represents another dimension of optimization. Rather than traditional key-value caching, the router stores semantic representations of prompts, enabling it to recognize semantically similar queries even when the exact wording differs. This intelligent similarity cache dramatically reduces token usage and latency by reusing responses for queries that are functionally equivalent even if textually distinct.
Perhaps most impressive is the auto-reasoning engine. This subsystem analyzes request complexity, domain expertise requirements, and performance constraints to automatically select not just which model to use, but how to configure that model for optimal results.
It considers factors like whether the query requires deep reasoning versus quick response, whether specialized domain knowledge is needed, and what the acceptable latency-cost tradeoffs are for this particular request.
Under the Hood: A Study in Engineering Excellence
The technical architecture of the vLLM Semantic Router reveals careful attention to both performance and maintainability. The system is implemented primarily in Go, chosen for its excellent concurrency support and deployment characteristics. A Rust binding layer leverages the Candle machine learning framework for BERT-based classification, combining Rust's memory safety guarantees with ML performance.
The repository structure reflects a mature, production-oriented project. The cmd directory contains the main application entry points, while the pkg directory houses reusable packages for routing logic, embedding generation, and cache management.
Training scripts in the src/training directory enable organizations to fine-tune classification models on their own data, adapting the system to specific domains or use cases.
Integration points are thoughtfully designed. The router implements the Envoy External Processing API, positioning itself between clients and LLM backends as an intelligent middleware layer. This allows it to intercept requests, perform classification and tool selection, modify the request payload, and then forward the optimized request to the appropriate backend - all while maintaining the standard OpenAI API interface that most tools and libraries expect.
The classification models themselves deserve special attention. Rather than using off-the-shelf transformers, the team fine-tuned ModernBERT specifically for intent classification tasks. These models are trained on carefully curated datasets that cover categories like mathematics, coding, business queries, creative writing, and more. The models are published on Hugging Face, making them accessible to the community and enabling reproducible results.
Real-World Applications and Success Stories
The versatility of the vLLM Semantic Router becomes apparent when examining real-world deployment scenarios. In enterprise settings, organizations use it to maintain cost control while providing employees access to a broad range of AI capabilities. A large technology company, for instance, deployed the router to manage access to over 500 internal AI tools. By automatically selecting only relevant tools for each request, they reduced their monthly inference costs by 87% while actually improving user satisfaction due to faster response times and more accurate tool selection.
For AI-powered customer service platforms, the router enables sophisticated multi-model architectures. Simple FAQ queries route to fast, efficient models, complex technical questions go to larger, more capable models, and queries requiring specific domain expertise are directed to specialized fine-tuned models. This tiered approach optimizes both cost and quality, ensuring customers get appropriate responses without over-provisioning expensive compute resources.
Development teams building AI agents find particular value in the semantic tool selection capabilities. When an agent needs to interact with dozens of APIs and services, the router ensures only relevant tools are loaded into context. This not only improves performance but also reduces the cognitive load on the language model, leading to fewer errors and more reliable agent behavior. One development team reported that implementing the Semantic Router reduced their agent's error rate by 64% while cutting API costs in half.
Research institutions leverage the router's flexibility to experiment with different model combinations. By defining custom routing rules and leveraging the training scripts to create domain-specific classifiers, researchers can quickly test hypotheses about optimal model selection strategies without rewriting application code. The comprehensive metrics and logging make it easy to analyze what's working and iterate rapidly.
Community and Contribution
The vLLM Semantic Router benefits from an active and growing community. The project's contribution guidelines are thorough and welcoming, with clear instructions for setting up development environments, running tests, and submitting changes. The team has implemented comprehensive pre-commit hooks that automatically check code quality, ensuring consistency across contributions.
Community engagement happens through multiple channels. Bi-weekly community meetings accommodate contributors across different time zones, with sessions at 9:00 AM EST on the first Tuesday and 1:00 PM EST on the third Tuesday of each month. These meetings provide opportunities to discuss the latest developments, share ideas, and coordinate on roadmap priorities. The project's Slack channel, #semantic-router in the vLLM workspace, offers real-time discussion and support.
The project has attracted attention from both industry and academia. Multiple research papers cite the Semantic Router's approach to tool selection, and it has been presented at conferences focused on MLOps and AI infrastructure. The team recently published "When to Reason: Semantic Router for vLLM," accepted at NeurIPS 2025 MLForSys, demonstrating the academic rigor underlying the practical engineering.
Current development activity, as evidenced by the 90 open issues, focuses on expanding gateway integrations beyond Envoy. The community is actively working on adding support for Istio, Kong, and other popular API gateways. There's also significant interest in improving the training pipeline to make it easier for organizations to create custom classifiers for specialized domains.
Usage and License Terms
The vLLM Semantic Router is released under the Apache License 2.0, one of the most permissive open-source licenses available. This choice reflects the project's commitment to broad adoption and commercial use. Under Apache 2.0, you are free to use the software for any purpose, distribute it, modify it, and distribute modified versions, all without requiring permission from the copyright holders.
The license does include some important provisions. You must include a copy of the Apache License in any distribution, state significant changes made to the software, and include a copy of any NOTICE file distributed with the software. Patent clauses in the license provide protection for both contributors and users: contributors grant patent licenses for any patents they hold that are necessarily infringed by their contributions, and these licenses terminate if you sue anyone over patents related to the software.
Practically speaking, this means organizations can deploy the Semantic Router in production environments, including commercial products, without licensing fees or restrictions. They can modify the code to suit their needs, even creating proprietary extensions, as long as they maintain the required license notices. This licensing approach has undoubtedly contributed to the project's adoption, particularly in enterprise settings where licensing concerns often slow down open-source adoption.
Impact and Future Potential
By demonstrating that semantic understanding can solve infrastructure challenges more effectively than traditional rule-based approaches, the project is influencing how the industry thinks about AI systems design. The Mixture-of-Models pattern it enables is becoming a recognized architectural pattern, with other projects adopting similar approaches.
Looking forward, the project's roadmap includes several ambitious features. Hierarchical retrieval will address performance as tool catalogs grow into the thousands by implementing two-stage retrieval that first selects relevant categories, then tools within those categories. Tool response management will tackle the complementary problem of handling large responses from tools, using intelligent parsing and progressive disclosure to avoid overwhelming context windows.
Multi-turn optimization represents another frontier. For long conversations involving many tool calls, the system will implement context compression, selective history inclusion, and sophisticated state management to maintain conversation quality while staying within context limits. These capabilities will be essential as AI assistants become more capable and handle increasingly complex, multi-step tasks.
The project's influence on the broader ML ecosystem is already apparent. The techniques pioneered here for semantic tool selection are being adopted by other projects, and the research findings about model performance degradation with large tool catalogs are informing best practices across the industry.
As the MCP (Model Context Protocol) ecosystem continues to grow - it already includes 4,400+ servers - the need for intelligent routing solutions like the Semantic Router becomes increasingly critical.
About the vLLM Project
The Semantic Router is part of the larger vLLM project, an open-source library for fast LLM inference and serving. The vLLM team, supported by contributions from leading technology companies and research institutions, has established itself as a major force in the AI infrastructure space. Their focus on production-ready, high-performance solutions has made vLLM a go-to choice for organizations deploying large language models at scale.
The team's expertise in both systems engineering and machine learning is evident throughout the Semantic Router's design. Features like the careful integration with Envoy, the choice of Rust for ML components, and the comprehensive monitoring and observability all reflect deep operational experience. The project benefits from the team's broader work on LLM serving, incorporating lessons learned from deploying inference systems handling billions of requests.
vLLM's commitment to open source is particularly noteworthy. Rather than keeping innovations proprietary, they consistently publish their work and engage with the community. This approach has created a vibrant ecosystem around their technologies, with contributions coming from users worldwide. The Semantic Router continues this tradition, offering a production-grade solution to a universal problem while inviting collaboration and improvement from the community.
Conclusion: The Future of AI Infrastructure is Semantic
The vLLM Semantic Router represents a fundamental advance in how we build and deploy AI systems. By addressing the tool overload problem with semantic tool intelligence rather than brute force, it enables architectures that were previously impractical or impossible.
The ability to maintain large catalogs of models and tools while actually improving performance and reducing costs changes the economics of AI deployment in ways that will have lasting impact.
As AI systems become more sophisticated and the number of available models continues to grow, intelligent routing won't be optional - it will be essential. The Semantic Router offers a production-ready solution today while continuing to evolve to meet tomorrow's challenges.
Whether you're building AI agents, developing customer-facing AI applications, or managing enterprise AI infrastructure, the principles and practices embodied in this project provide a roadmap for scaling effectively.
For developers and organizations ready to move beyond static model selection and embrace context-aware routing, the Semantic Router provides everything needed to get started: comprehensive documentation, Docker Compose and Kubernetes deployment options, a quickstart script that sets up a complete system in minutes, and an active community ready to help.
The project's combination of technical excellence, operational maturity, and open collaboration makes it an exemplar of modern open-source infrastructure software. Explore the repository on GitHub, review the documentation, and consider how semantic routing could transform your AI systems.
References:


Semantic Tool Intelligence: vLLm Context-Aware Tool Router Solves the Tool Overload Crisis