Large language model applications rarely involve a single task or a single best model. A customer conversation can shift from arithmetic to code to creative writing within minutes. The vLLM Semantic Router proposes a practical answer: place a small, fast classifier in front of your models, screen inputs for safety, consult a semantic cache, then route each request to the most suitable backend via an OpenAI-compatible API.
This review distills what the project does, how it works, when to use it, and how to adopt it safely and observably in production.

vllm-project
Organization
semantic-router
Intelligent Mixture-of-Models Router for Efficient LLM InferenceKey Takeaways
- Task-aware routing: A lightweight CPU-friendly classifier chooses a model per request, improving quality and cost stability on mixed workloads (Fedus, 2021).
- Security at the edge: PII and jailbreak checks enforce policy before prompts reach providers, in line with OWASP LLM Top 10 guidance (OWASP, 2025).
- Drop-in surface: OpenAI-compatible chat/completions API plus routing metadata for downstream logs and dashboards (Envoy, 2025).
- Semantic caching: Vector similarity deduplicates work; foundations align with FAISS-style ANN search (Johnson, 2017).
- Production-minded: Built on Envoy ExtProc with Prometheus metrics, timeouts, retries, and circuit breaking (Envoy, 2025).
What It Does
The Semantic Router is an API gateway for LLMs that adds intent classification, safety screening, and cache-aware dispatch. It sits between your clients and providers, choosing a backend model per request and attaching routing metadata for analytics and auditing. It aims to reduce cost variance, improve task fit, and make policy enforcement explicit.
Architecture And Flow
Envoy handles HTTP and streams request headers and bodies to the router service via the External Processing (ExtProc) filter. The router (written in Go) runs fast CPU inference using ModernBERT-style classifiers (BERT-family finetunes) and applies your policies.
It returns headers such as x-selected-model and x-routing-confidence, which Envoy forwards to the chosen upstream. Prometheus and access logs capture per-stage latencies, classifier outcomes, and cache hit ratios (Envoy, 2025); (Devlin, 2019).
Training And Models
The repo provides Python utilities for preparing datasets and finetuning classifiers for intents like math, code, and creative writing, plus safety detectors (PII, jailbreak). Inference uses Rust Candle backends to keep per-request overhead low on commodity CPUs.
The approach follows the well-tested pretrain-then-finetune pattern popularized by BERT and its successors (Devlin, 2019). Conceptually, you can view the system as a coarse Mixture-of-Experts: a small router sends each input to the most suitable expert model, echoing ideas from Switch Transformer routing (Fedus, 2021).
Configuration And Cost
You declare categories, thresholds, providers, and per-1M token prices in configuration files (see config/). Downstream services can log metadata via headers such as x-selected-model, x-routing-confidence, and x-processing-time.
A simple unit cost formula is: cost = (prompt_tokens * p + completion_tokens * c) / 1,000,000, where p and c are your configured per-1M token rates. Tracking this alongside routing decisions helps teams choose model tiers (for example, reasoning vs baseline) for each category.
Security And Safety
Boundary checks are applied before any provider sees the prompt. PII detection lets you block, mask, or transform inputs; jailbreak guards help contain prompt injection and unsafe content.
These controls align with OWASP GenAI best practices for input filtering, monitoring, and defense-in-depth (OWASP, 2025). Treat them as complementary to red teaming, human review, and end-to-end evaluation, not a replacement.
Semantic Caching
The router can consult a vector cache of prior requests and generations. If a new request is sufficiently similar to a cached one, it can return the prior result or use it as a seed. This is an approximate nearest neighbor problem; FAISS-style indexes demonstrate that high recall is possible at low latency with proper tuning (Johnson, 2017). In practice you can pair a similarity threshold with time-based invalidation and provenance tags so dashboards can distinguish cache hits from live inference.
How To Use It
Start with the Installation Guide and the System Architecture overview.
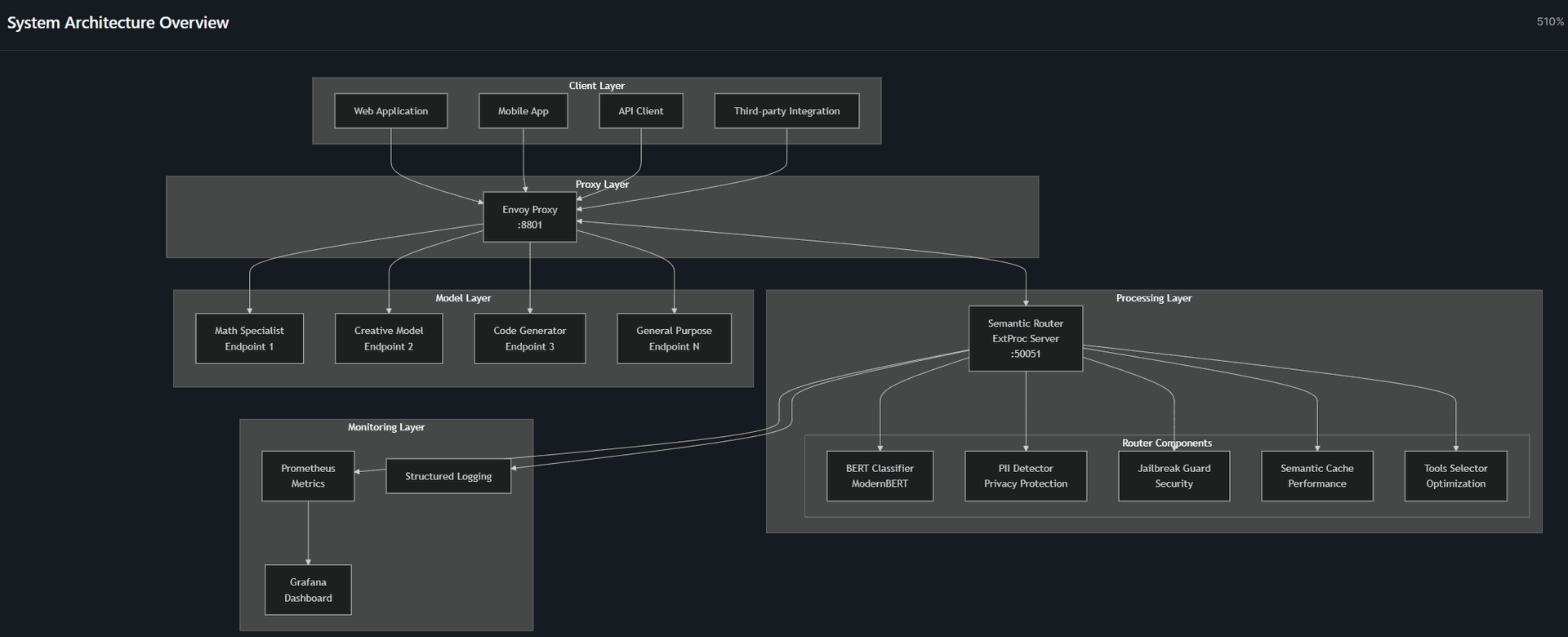
Define a small set of categories that reflect your traffic (for example, math, code, creative, summarization) and set conservative thresholds. Route a fraction of production traffic through the gateway and compare quality, latency, and cost to baselines then continue to add safety rules next, then experiment with semantic caching and model tiers.
Example Client Call
import requests
BASE_URL = "http://localhost:8801" // The vLLM Semantic Router proxy
payload = {
"model": "auto",
"messages": [
{"role": "user", "content": "Compute the integral of x^2 from 0 to 3 and show steps."}
],
"max_tokens": 200,
}
r = requests.post(f"{BASE_URL}/v1/chat/completions", json=payload, timeout=20)
r.raise_for_status()
resp = r.json()
print(resp.get("routing_metadata", {})) # Or inspect response headers if configured.
print(resp["choices"][0]["message"]["content"])
Deployment And Observability
Envoy gives you battle-tested controls for timeouts, retries, hedging, and circuit breaking. The ExtProc filter exposes counters and latencies for header and body processing, and gRPC status; publish these to Prometheus and include routing metadata in access logs.
If you enable failure_mode_allowed, Envoy will avoid request loss when the router is down by skipping processing, but you may lose policy enforcement or select a default model. Use this only with alarms and dashboards to catch degraded routing (Envoy, 2025).
Evaluation And Ops
To validate routing, build a labeled holdout set with your most common intents and safety cases. Track confusion matrices for the classifier, cache hit ratios, and per-model unit cost. Add guardrail metrics like jailbreak detection rates and PII mask coverage. For incident response, you can capture enough metadata (request ID, selected model, thresholds, cache provenance) to reproduce routing decisions post hoc. This keeps SRE and security teams in the loop.
Use Cases
This pattern shines when traffic is heterogeneous or cost-sensitive. Examples include customer support that mixes retrieval, summaries, and creative replies; tutoring systems that alternate between computation and explanation; and coding assistants where lightweight models can handle boilerplate while complex reasoning falls back to stronger models. Teams with strict compliance needs benefit from boundary screening and auditable routing logs.
Limitations And Edge Cases
Routing depends on classifier quality. Expect to retune thresholds, retrain as distributions drift, and define fallbacks for unknown or mixed intents. Cache reuse can return stale or undesired outputs without freshness windows or safety re-checks so be sure to set end-to-end timeouts to avoid head-of-line blocking, and ensure idempotency so retried requests do not duplicate side effects.
Related Work
Mixture-of-Experts research established sparse activation with per-input routing; the Switch Transformer simplified gating for scale (Fedus, 2021). BERT showed the effectiveness of pretraining followed by task-specific finetuning, which modern CPU-efficient classifiers inherit (Devlin, 2019).
While FAISS demonstrated high-performance approximate nearest neighbor search that underpins many vector databases and semantic caches (Johnson, 2017). At the edge, Envoy's ExtProc filter offers the integration point and telemetry for safe, observable routing (Envoy, 2025).
Conclusion
An intent-aware gateway is a pragmatic way to raise quality and control cost when your workloads vary. The vLLM Semantic Router combines Envoy reliability, CPU-fast classification, semantic caching, and an approachable API. Start small, measure often, and expand categories and policies as your data teaches you. See the Installation Guide and System Architecture for concrete steps, and review the source to adapt the router to your environment.
References
(Envoy, 2025); (Devlin, 2019); (Fedus, 2021); (Johnson, 2017); (vLLM Semantic Router Docs, 2025).


Intent-Aware LLM Gateways: A Practical Review of vLLM Semantic Router