In the world of machine learning, AI and data science, embeddings have become the universal translator for complex data. Whether you are analyzing customer feedback, exploring research papers, or understanding image collections, embeddings transform intricate information into mathematical representations that machines can process to uncover semantic relationships.
But there is a catch: these high-dimensional vectors are notoriously difficult for humans to understand. Apple's Embedding Atlas looks to provide a powerful, open-source tool that transforms the abstract world of embeddings into interactive, visual experiences that anyone can explore.

apple
Organization
Released under the MIT license in 2025, Embedding Atlas represents Apple's commitment to advancing data visualization and making sophisticated machine learning tools accessible to researchers, developers, and data scientists worldwide.
The project emerged from the need to eliminate the tedious setup processes, scalability limitations, and lack of integration with existing workflows that plague many existing tools.
The result is a platform that handles millions of data points with remarkable speed while providing rich, interactive analysis capabilities that keep pace with modern data science demands.
Key Takeaways
- Automatic data clustering and labeling for instant visualization of data structure
- Kernel density estimation with contours to distinguish dense regions from outliers
- Order-independent transparency for accurate rendering of overlapping points
- Real-time search and nearest neighbor queries for finding similar data instantly
- WebGPU implementation with WebGL 2 fallback for smooth performance up to millions of points
- Multi-coordinated views enabling interactive filtering across metadata dimensions
- Simple command-line tool and Jupyter widget for seamless workflow integration
- Modular architecture with React, Svelte, and vanilla JavaScript components
- WebAssembly-powered Rust and C++ algorithms for high-performance browser computation
- MIT License allowing free use in both academic research and commercial applications
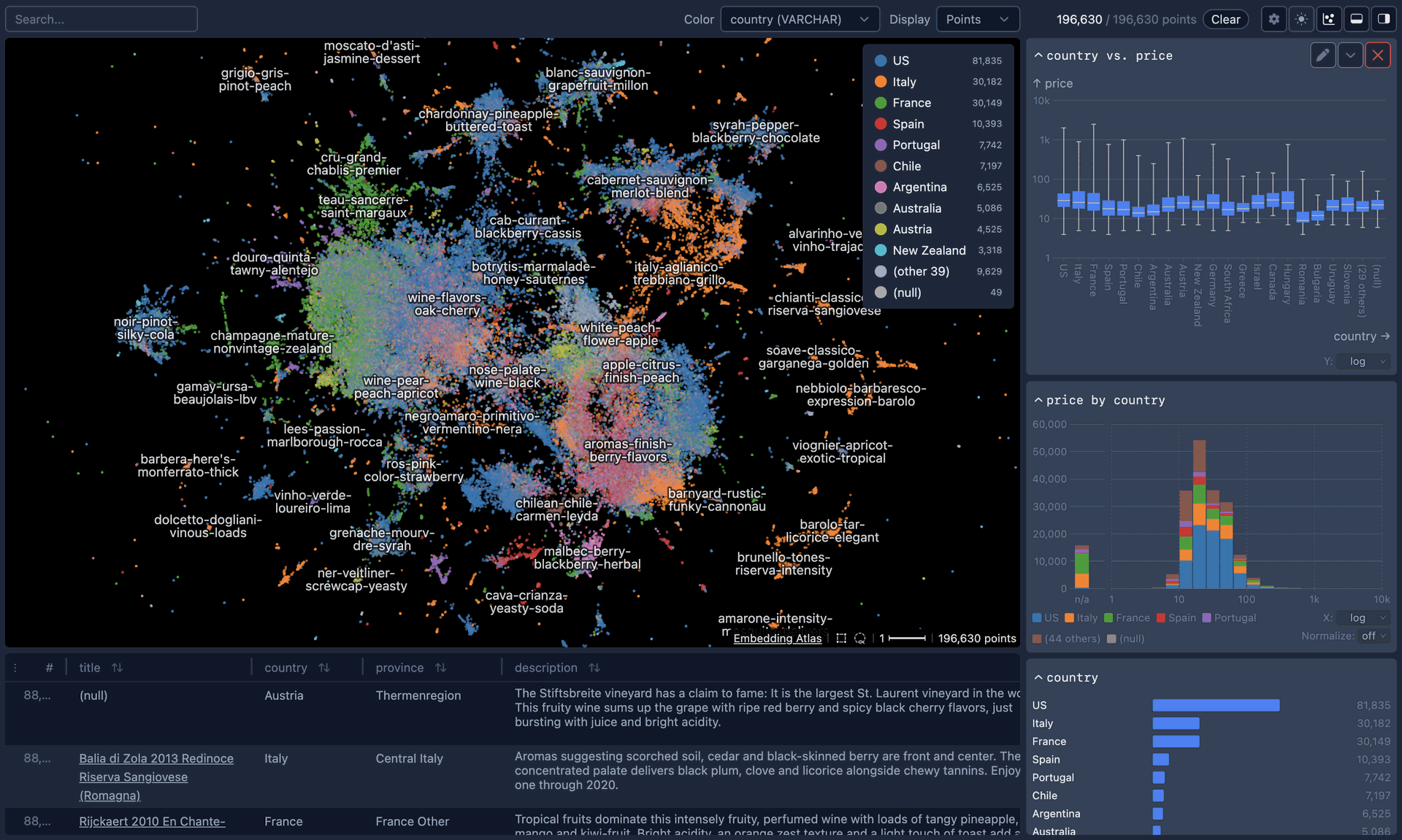
Image Credit: Apple
Key Features
Embedding Atlas comes packed with features designed to reduce friction and enhance the exploration of large-scale embeddings. At its core, the tool provides automatic data clustering and labeling, allowing you to instantly visualize and navigate the overall structure of your dataset.
The system employs kernel density estimation and density contours, making it effortless to distinguish between dense clusters of similar data and outliers that deserve closer inspection.
One of the standout technical achievements is its implementation of order-independent transparency, ensuring that overlapping points render clearly and accurately regardless of viewing angle or zoom level.
The platform's real-time search and nearest neighbor capabilities let you find similar data points instantly, whether you're querying with new input or exploring relationships between existing points. Built on WebGPU with a WebGL 2 fallback, Embedding Atlas delivers smooth performance with datasets containing up to several million points, leveraging modern rendering technologies to maintain responsiveness even during complex interactions.
Perhaps most valuable for practical data analysis, the tool provides multi-coordinated views for metadata exploration, enabling you to interactively link and filter data across multiple dimensions and metadata columns simultaneously.
The Problem and The Solution
Working with embeddings has traditionally been an exercise in frustration. Data scientists may spend valuable time wrangling data into the right format, only to discover that their visualization tool cannot handle the dataset's size.
Integration with existing workflows often requires custom scripting and manual exports. Perhaps most limiting, many tools provide only the embedding visualization itself, without the ability to cross-reference with metadata or perform coordinated filtering across different views of the same data. These pain points create significant barriers to adoption and limit the depth of analysis possible.
Embedding Atlas offers a combination of thoughtful design and technical innovation. The tool accepts standard data formats like Parquet file. It scales to millions of points through efficient rendering algorithms and data structures.
The Python package integrates seamlessly into existing workflows as both a command-line tool and a Jupyter notebook widget, while the npm packages provide components for React, Svelte, and vanilla JavaScript applications. By combining the embedding visualization with coordinated metadata views, the platform enables richer analysis patterns that would require multiple separate tools with traditional approaches.
Why I Like It
What makes Embedding Atlas particularly impressive is its dedication to removing barriers between users and their data. The command-line interface could not be simpler: you simply install the package and point it at your data file. Within seconds, you're exploring your embeddings in a browser with full interactivity.
For those working in notebooks, the widget integration feels natural and responsive, maintaining the exploratory flow that makes Jupyter such a powerful research tool. The attention to performance details like order-independent transparency and WebGPU rendering shows a commitment to quality that extends beyond just making something work to making it work beautifully.
The project's architecture reveals careful thought about modularity and reusability. Rather than building a monolithic application, the team structured Embedding Atlas as a collection of focused packages: separate components for the embedding view, table display, density clustering, and UMAP projection.
This design means developers can cherry-pick the pieces they need for their own applications, while researchers get a complete solution out of the box. The inclusion of both WebAssembly implementations of computationally intensive algorithms like density clustering and UMAP demonstrates a willingness to invest in performance where it matters most.
Under the Hood
The project is organized as a monorepo containing multiple specialized packages. On the frontend, packages/component provides the core EmbeddingView and EmbeddingViewMosaic components, while packages/table handles the metadata table display. The packages/viewer package ties these together into the complete frontend application and provides embeddable components for other frameworks.
The technology choices reveal a focus on performance and developer experience. The frontend leverages Svelte 5 for reactive UI components, providing excellent runtime performance with minimal framework overhead.
For data processing in the browser, the project employs DuckDB-WASM, bringing powerful SQL capabilities directly to the client side. The visualization layer builds on the Mosaic framework from the UW Interactive Data Lab, which provides coordinated multiple views and efficient data management. TypeScript provides type safety across the JavaScript packages, while Vite handles the build pipeline with fast development server performance.
Two packages demonstrate particular technical sophistication.
- The packages/density-clustering directory contains a Rust implementation of density-based clustering algorithms, compiled to both WebAssembly for browser use and native binaries for server-side processing.
- Similarly, packages/umap-wasm wraps the umappp C++ library in WebAssembly, enabling fast dimensionality reduction calculations in the browser. These WebAssembly modules allow Embedding Atlas to perform computations that would traditionally require server-side processing, reducing latency and improving the user experience.
The Python backend, located in packages/backend, provides the embedding-atlas command-line tool and Jupyter widget. Built with FastAPI and Uvicorn, the server provides efficient data serving and computation endpoints.
The package integrates with the sentence-transformers library for generating embeddings from text, UMAP-learn for dimensionality reduction, and PyArrow for efficient data serialization. The widget implementation uses the anywidget specification, providing a clean interface between Python and JavaScript that works across different notebook environments.
Use Cases
Embedding Atlas shines in scenarios involving large-scale text analysis.
- Natural language processing researchers can visualize document collections to understand thematic clustering, identify outliers, and explore the semantic relationships between texts.
- Customer feedback analysis becomes more intuitive when support teams can visualize thousands of customer reviews as embeddings, quickly identifying common themes and unusual complaints that deserve attention.
- Content recommendation systems benefit from being able to visualize and understand the similarity space of articles, products, or media items.
- The tool proves equally valuable for image analysis tasks. Computer vision researchers can explore how different image embedding models cluster visual concepts, comparing model behaviors and identifying edge cases.
- Art and media archives can provide browsable interfaces to large collections, letting users explore visual similarity relationships intuitively.
- In the biological sciences, researchers working with single-cell sequencing data have already adopted Embedding Atlas, as evidenced by community requests for expanded legend capabilities to handle the numerous cell type annotations common in genomics research.
- Beyond research, Embedding Atlas serves practical engineering needs. Machine learning engineers can use it to debug embedding models, visualizing how model changes affect the learned similarity space.
- Data quality teams can identify anomalies and outliers in production datasets by examining their position in the embedding space relative to typical examples.
The tool's ability to handle millions of points makes it suitable for real-world production datasets, not just toy examples or research prototypes.
Community and Contribution
The Embedding Atlas project maintains an active and growing community. The issue tracker reveals engaged users requesting features like image display in the UI, enhanced selection APIs, and improved handling of large coordinate values.
The development team, led by researchers Donghao Ren, Fred Hohman, Halden Lin, and Dominik Moritz, actively responds to issues and merges community contributions. Recent activity shows consistent improvements: code editor upgrades, performance optimizations, and bug fixes that demonstrate ongoing maintenance and development.
For those interested in contributing, the project provides clear guidelines in CONTRIBUTING.md. The maintainers welcome issues and pull requests, with a process that balances community involvement with the realities of maintaining a complex project.
The architecture's modularity makes it possible to contribute to specific components without understanding the entire codebase. The project follows Apple's standard Code of Conduct, ensuring a welcoming environment for contributors from diverse backgrounds.
The academic foundation adds credibility and provides a roadmap for future development. The project links to two arXiv papers: the main paper on Embedding Atlas itself and a second paper detailing the scalable clustering algorithm used for automatic labeling.
These publications provide detailed insights into the algorithms and design decisions, making the project particularly valuable for researchers who want to understand and potentially extend the underlying methods.
Usage and License Terms
Embedding Atlas is released under the MIT License, one of the most permissive open-source licenses available. This means you can freely use, modify, and distribute the software for any purpose, including commercial applications, with minimal restrictions.
The only requirements are that you include the original copyright notice and license text in any copies or substantial portions of the software. You can integrate Embedding Atlas components into proprietary applications, fork the repository to create customized versions, or use it as a foundation for research projects without worrying about licensing complications.
The MIT License also provides important liability protections, explicitly stating that the software is provided "as is" without warranties of any kind. This standard clause protects the contributors while giving users the freedom to adopt the software with confidence. For organizations evaluating open-source tools, the MIT License represents minimal legal risk and maximum flexibility, making Embedding Atlas suitable for both academic research and commercial product development.
Impact and Future Potential
By dramatically reducing the friction involved in exploring embeddings, it lowers the barrier to entry for data scientists and researchers who might otherwise avoid working with high-dimensional representations helping to reveal new features and identify areas of concern.
The tool's emphasis on performance at scale addresses a real limitation in the field that many existing tools become unusably slow with realistic dataset sizes. The ability to handle millions of points in real-time means practitioners can work with production-scale data, not just samples or toy datasets.
The modular architecture positions Embedding Atlas as infrastructure rather than just an application. Developers building custom data exploration tools can leverage the embedding view component, the density clustering implementation, or the UMAP WebAssembly module independently.
This composability multiplies the project's impact, as improvements and optimizations benefit not just users of the complete application but anyone building related tools. The choice to implement performance-critical algorithms in Rust and compile to WebAssembly establishes patterns that other projects can follow.
Looking forward, the project's trajectory suggests continued evolution with community requests for image display capabilities point toward expanding beyond text embeddings to multimedia analysis. The active issue around selection APIs indicates growing use of Embedding Atlas as a component in larger applications rather than just a standalone tool.
As embedding-based approaches continue to proliferate across machine learning applications, having robust, performant visualization tools becomes increasingly critical. Embedding Atlas is well-positioned to evolve with these needs, backed by research-driven development and an active community.
About Apple
Apple Inc. is a global technology leader known for innovative consumer electronics, software platforms, and services. Beyond its commercial products, Apple maintains an active open-source presence on GitHub, contributing to and releasing projects that advance various areas of computing. The company's machine learning research team publishes peer-reviewed papers and releases open-source tools that benefit the broader research community. Embedding Atlas represents this commitment to advancing the state of the art in data visualization and making powerful tools accessible beyond Apple's internal use.
Apple's approach to open source balances commercial interests with genuine community engagement. Projects like Embedding Atlas demonstrate the company's investment in fundamental research problems that affect the entire field of machine learning and data science. By releasing such tools under permissive licenses, Apple contributes to the ecosystem while building goodwill and relationships with academic and industrial researchers. This strategy benefits Apple by improving the tools and techniques that ultimately feed back into their products, while advancing the field for everyone.
Conclusion
Embedding Atlas represents a significant contribution to the data visualization landscape, addressing real pain points that practitioners face daily. Its combination of performance, ease of use, and powerful features makes it a valuable tool for anyone working with embeddings, from academic researchers to production ML engineers.
The thoughtful architecture and choice of modern technologies ensure that the project can evolve with the field's needs, while the permissive MIT License removes barriers to adoption.
Whether you are exploring customer feedback, analyzing research papers, debugging embedding models, or building custom data exploration tools, Embedding Atlas deserves a place in your toolkit.
The project exemplifies how thoughtful design and technical excellence can remove friction from complex workflows, making sophisticated analysis accessible to more people. Visit the project website to try the demo, explore the GitHub repository to dive into the code, or install the package and start visualizing your own embeddings. The future of data exploration is interactive, scalable, and open source.


Apple Embedding Atlas: Making Sense of Millions Through Interactive Visualization