Recent advancements in large language models (LLMs) have significantly improved natural language understanding, but generalizable text embeddings remain a challenge. This research by Google DeepMind introduces Gemini Embedding, a state-of-the-art embedding model leveraging Google's Gemini LLM, designed to create high-quality vector representations across multiple languages and textual modalities.
Key Takeaways
- Multilingual Generalization: Gemini Embedding supports over 250 languages, outperforming prior state-of-the-art models.
- Superior Benchmark Performance: It achieves first-place rankings on the Massive Multilingual Text Embedding Benchmark (MMTEB) across multilingual, English, and code tasks.
- Optimized Training Process: Utilizes contrastive learning, hard negative mining, and synthetic data generation to enhance embedding quality.
- Robust Retrieval Capabilities: Excels in text classification, clustering, ranking, and retrieval, even in low-resource languages.
- Potential for Multimodal Expansion: Future work aims to extend embedding capabilities to image, video, and audio data.
- Versatility: The model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
- Potential Applications: The model can be precomputed and applied to a variety of downstream tasks, making it useful for tasks like information retrieval, clustering, and classification in multilingual and code-related contexts.
Overview
Embedding models transform textual inputs into dense vector representations, allowing for semantic comparisons across various applications such as search, recommendation systems, and natural language processing (NLP). While prior models like Sentence-BERT (Reimers & Gurevych, 2019) and Universal Sentence Encoder (Cer et al., 2018) provided strong results, their generalization across diverse languages and domains was limited.
Text embedding models, in particular, represent words and sentences as vectors, positioning semantically similar texts close to each other in the embedding space (Gao et al., 2021; Le and Mikolov, 2014; Reimers and Gurevych, 2019). Recent research has focused on developing general-purpose embedding models that excel in diverse downstream tasks, including information retrieval, clustering, and classification (Cer et al., 2018; Muennighoff et al., 2023).
The rise of LLMs has revolutionized embedding strategies, enabling richer representations by leveraging extensive pre-training data. Gemini Embedding capitalizes on this by initializing embeddings from Gemini, benefiting from its vast multilingual and multimodal knowledge.
Gemini Embedding is initialized from the powerful Gemini large language model (Anil et al., 2023a; Team, 2024). It is trained on a comprehensive suite of embedding tasks, utilizing Gemini for several critical data curation steps: filtering low-quality examples, determining relevant positive and negative passages for retrieval, and generating rich synthetic datasets.
The model incorporates task prompts and a pre-finetuning stage to enhance performance. Additionally, it uses Model Soup (Wortsman et al., 2022), a parameter averaging technique, to combine multiple fine-tuned checkpoints, yielding a superior final embedding model.
Why It’s Important
Gemini Embedding represents a significant advancement in the field of embedding models, particularly in its ability to handle multilingual and code-related tasks. The model's state-of-the-art performance across various benchmarks highlights its potential to improve a wide range of applications, from information retrieval to classification and clustering.
Its ability to generate highly generalizable embeddings makes it a valuable tool for researchers and developers alike, enabling more efficient and effective processing of textual data across multiple languages and domains.
The use of Gemini Embedding in precomputed and cached representations opens up new possibilities for applying the power of Gemini in compute and latency-sensitive settings. This could lead to more efficient and scalable solutions for tasks that require real-time processing or have limited computational resources.
Gemini Embedding addresses key challenges in multilingual NLP and cross-domain generalization, making it a breakthrough in several fields:
- Scalability & Efficiency: Precomputed embeddings reduce computational demands, allowing real-time application in retrieval and ranking tasks.
- Cross-Language Alignment: Facilitates improved machine translation, multilingual search, and document similarity detection.
- Enhanced Information Retrieval: Strengthens semantic search, leading to more accurate and context-aware query results across languages and domains.
- Improved AI Assistants: Enables virtual assistants to better understand queries in multiple languages and respond more accurately.
- Advancements in Code Intelligence: Supports code search and recommendation systems, benefiting software development and AI-driven programming tools.
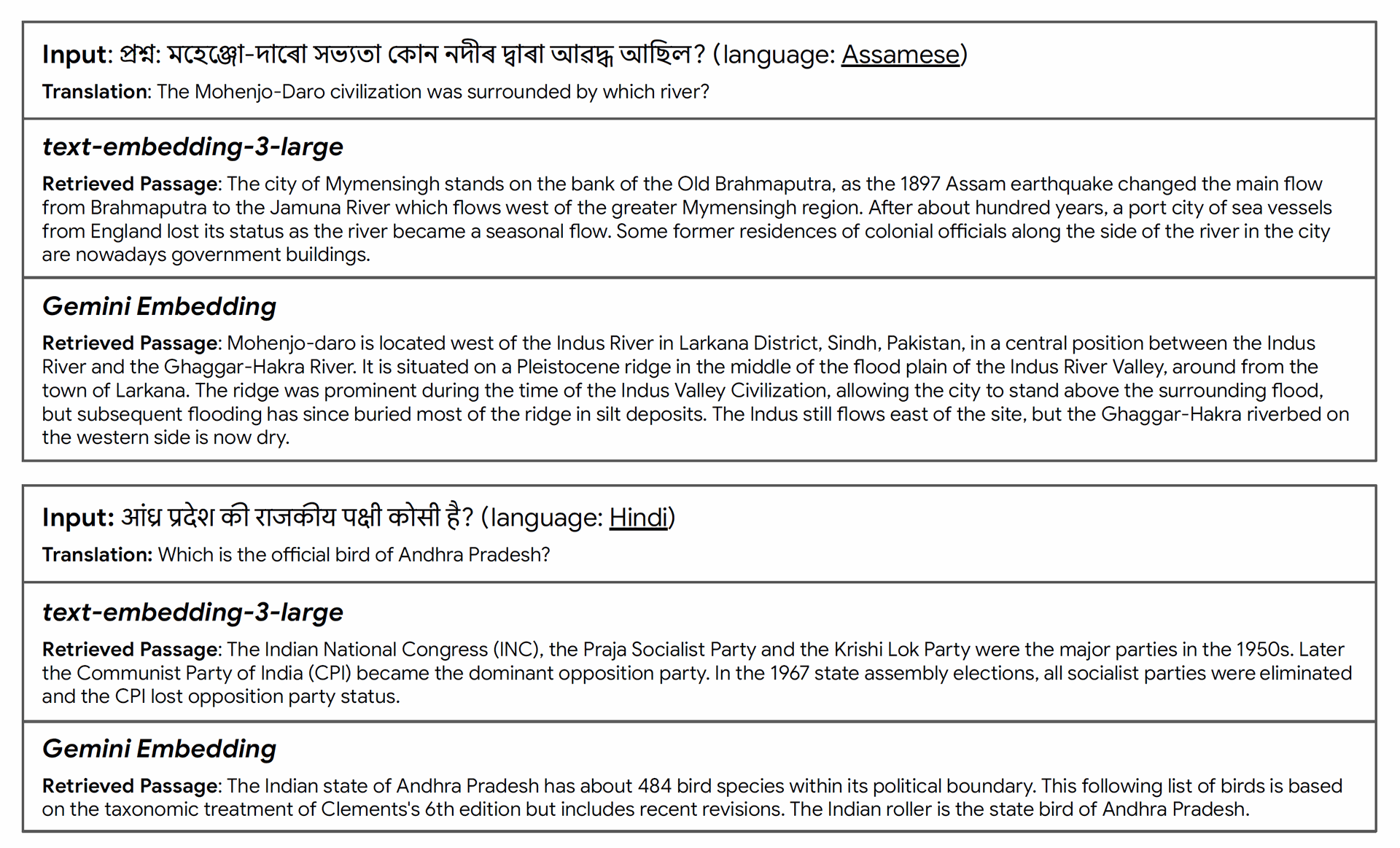
Figure 2 | Gemini Embedding supports cross-lingual retrieval where different languages can be used for queries and passages. We show two examples from XTREME-UP showing the strong cross-lingual retrieval capability of Gemini Embedding. Despite Assamese being a relatively low-resource language and the Hindi query having a typo, the Gemini Embedding model correctly understood the key entities and the contexts in the queries and retrieved the correct passages.
How Embeddings Work
Embeddings are a fundamental concept in machine learning, particularly in the domain of natural language processing (NLP) and recommendation systems.
They are dense vector representations of data, where each data point is mapped to a high-dimensional vector space. This mapping allows machines to understand and process complex data more efficiently.
Embeddings work by converting categorical or textual data into numerical formats that can be understood by machine learning algorithms. Here's a simplified explanation of how embeddings work:
- Input Data: The process begins with input data, which can be text, images, or categorical data. For instance, consider the sentences "The cat sits on the mat" and "The dog sits on the log."
- Embedding Model: The input data is fed into an embedding model, typically a neural network trained to understand the semantic meaning of the data. For example, a sentence embedding model like Sentence-BERT can be used.
- Vector Representation: The embedding model converts the input data into a dense vector representation. This vector captures the semantic meaning of the input data in a high-dimensional space. For the sentences above, the model might produce vectors like [0.25, 0.1, ..., 0.8] for the first sentence and [0.2, 0.15, ..., 0.75] for the second.
- Similarity Measurement: The vectors can then be used to measure similarity between different data points. Common similarity measures include cosine similarity and Euclidean distance. In our example, the cosine similarity between the two vectors might be 0.9, indicating high semantic similarity.
- Downstream Tasks: The vector representations can be used for various downstream tasks such as classification, clustering, and recommendation systems. For instance, the vectors can be used to classify the sentences into categories or to recommend similar sentences.
Types of Embeddings
- Word Embeddings: These are vector representations of words, where semantically similar words are close to each other in the vector space. Examples include Word2Vec and GloVe.
- Sentence Embeddings: These are vector representations of sentences, capturing the meaning of the entire sentence. Examples include Sentence-BERT and Universal Sentence Encoder.
- Image Embeddings: These are vector representations of images, capturing the visual features of the image. Examples include convolutional neural networks (CNNs) used for image classification.
- Graph Embeddings: These are vector representations of nodes in a graph, capturing the structural information of the graph. Examples include Node2Vec and DeepWalk.
Advantages of Embeddings
- Dimensionality Reduction: Embeddings reduce the dimensionality of data, making it easier to process and analyze.
- Semantic Similarity: Embeddings capture semantic similarity between data points, allowing for more accurate and meaningful comparisons.
- Generalization: Embeddings can generalize well to new and unseen data, making them robust for various applications.
Challenges of Embeddings
- Computational Complexity: Training embedding models can be computationally intensive, requiring significant resources.
- Interpretability: Embeddings are often difficult to interpret, as they are high-dimensional vector representations.
- Data Requirements: Embedding models require large amounts of data to train effectively.
Embeddings are a powerful tool in machine learning, enabling machines to understand and process complex data more efficiently. They have wide-ranging applications and continue to be an active area of research and development.
How Embeddings Are Used
Embeddings serve as the foundation for numerous NLP applications, allowing textual data to be mapped into a shared numerical space where similar meanings are closer together. Gemini Embedding enhances the following key areas:
- Search & Information Retrieval: Semantic search and ranking for improved relevance in query-matching systems.
- Machine Translation & Cross-Language Understanding: Enhanced alignment between different language inputs, improving document retrieval and summarization.
- Question Answering & Chatbots: Strengthens contextual understanding, enabling more accurate responses in conversational AI.
- Code Understanding & Generation: Supports programming-related embeddings, improving code search and retrieval.
- Content Recommendation Systems: Enhances the ability to suggest relevant documents, articles, and media based on textual similarities.
- Natural Language Processing (NLP): Text classification, sentiment analysis, and machine translation.
- Recommendation Systems: Recommend products, movies, or content to users based on their past behavior and preferences.
- Image Recognition: Object detection and image classification.
- Graph Analysis: Node classification and link prediction.
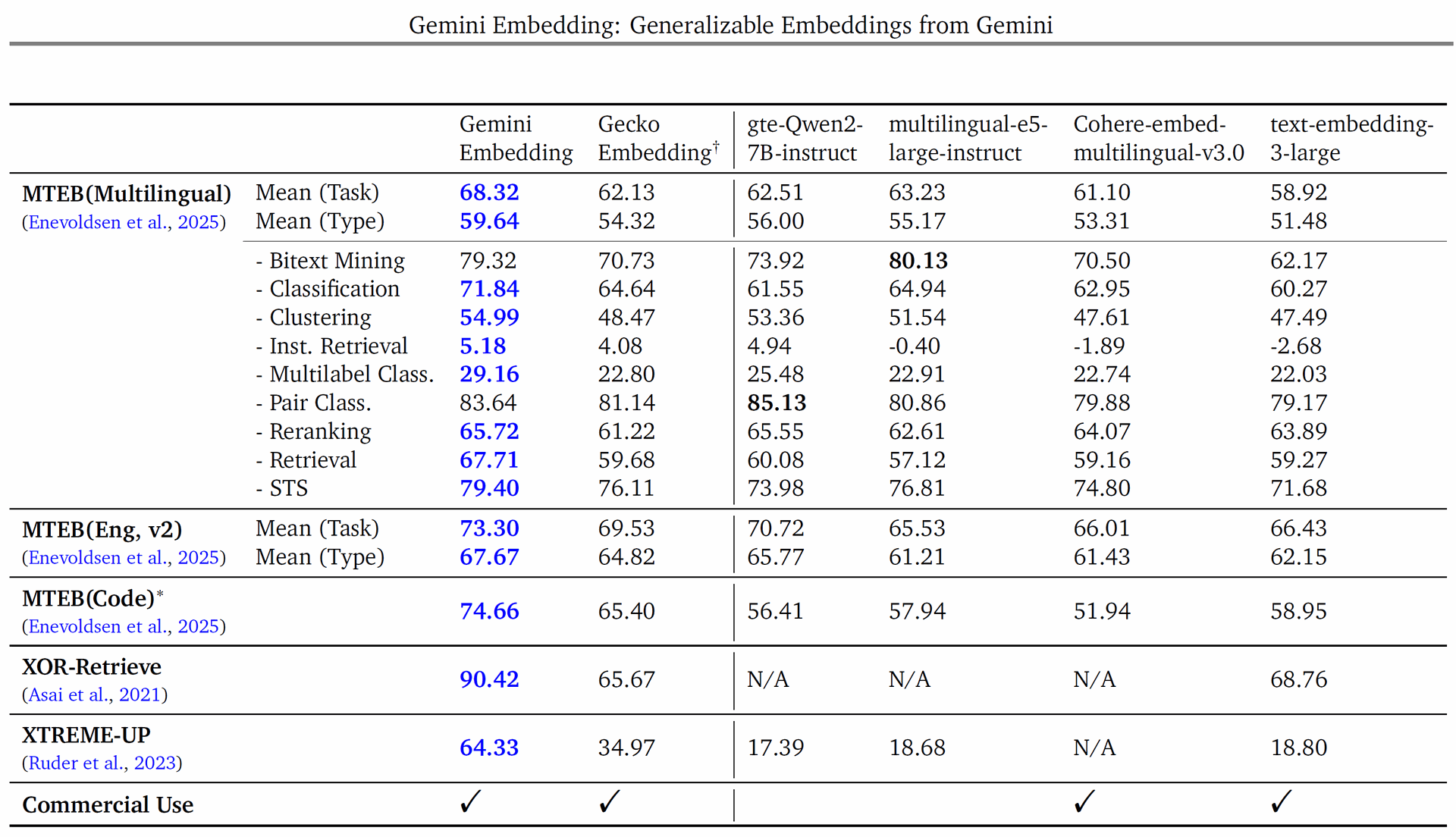
Table 1 | Comparison of embedding models on Massive Multilingual Embedding Benchmark: MTEB(Multilingual), MTEB(Eng, v2), and MTEB(Code). We also show results on XOR-Retrieve and XTREME-UP. For MTEBs, we report task and type mean performances. We report MRR@10 for XTREME-UP and Recall@5kt for XOR-Retrieve. ∗: Averaged over seven code tasks available for all models. †: For Gecko Embedding (Lee et al., 2024), we evaluate text-embedding-004 on MTEB(Eng, v2), text-embedding-005 on MTEB(Code), and text-multilingual-embedding-002 on others.
Training Methodology
Gemini Embedding employs a two-stage training pipeline designed to optimize efficiency and generalization:
Pre-Finetuning Stage
- Uses a diverse web-scale corpus to expose the model to a wide variety of textual structures.
- Focuses on high-quality text filtering to eliminate noise, ensuring robust representation learning.
- Employs self-supervised learning with contrastive objectives to enhance retrieval-based tasks.
Fine-Tuning Stage
- Incorporates hard negative mining, improving discrimination between closely related yet distinct text pairs.
- Optimized using multi-task learning, balancing multiple tasks such as classification, clustering, and retrieval.
- Model Souping Technique: Merges different trained checkpoints to enhance generalization without overfitting.
Summary of Results
Gemini Embedding was evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over 100 tasks across 250+ languages. The model achieved state-of-the-art performance on MMTEB(Multilingual), significantly surpassing the previous best models.
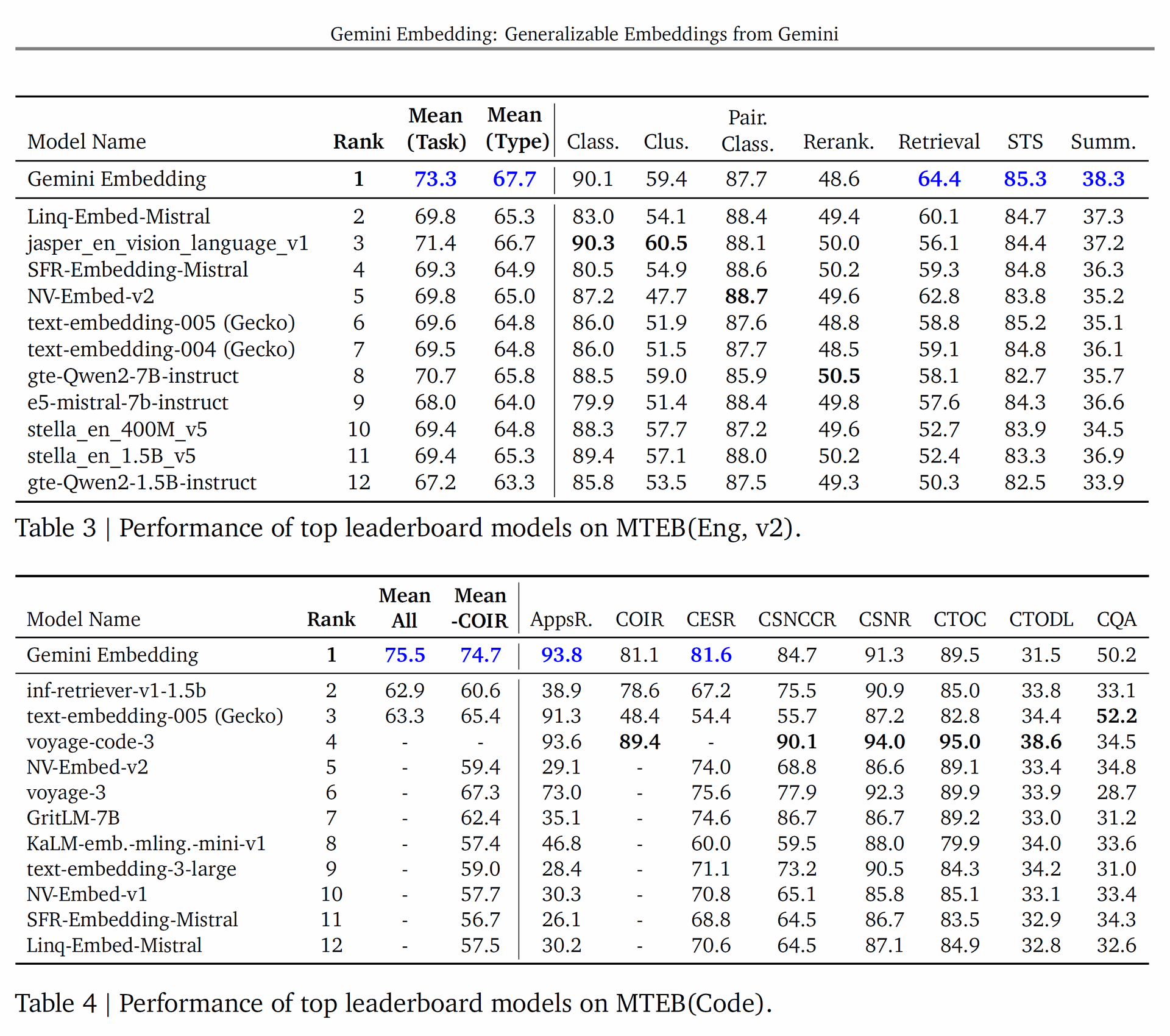
It also achieved the highest overall performance on the MTEB(Eng, v2) and MTEB(Code) benchmarks, demonstrating its versatility and robustness.

Table 2 | Performance of top leaderboard models on MTEB(Multilingual).
Synthetic data generation, data filtering, and hard negative mining were also shown to improve the quality of the training data, leading to better model performance.
Proper filtering of retrieval datasets using LLMs and the use of multi-stage prompting strategies for generating synthetic datasets were particularly effective.
The key experiments and findings include:
Benchmark Performance
- MMTEB (Massive Multilingual Text Embedding Benchmark)
- #1 ranking on MMTEB (Multilingual): Mean task score of 68.32, surpassing multilingual-e5-large-instruct.
- #1 ranking on MMTEB (English, v2): Mean task score of 73.30, outperforming previous top models.
- #1 ranking on MMTEB (Code): Mean task score of 74.66, leading in programming-related embedding tasks.
- Cross-Lingual Retrieval Performance
- XOR-Retrieve (Asai et al., 2021): Recall@5k score of 90.42, demonstrating superior retrieval capabilities.
- XTREME-UP (Ruder et al., 2023): 64.33 MRR@10, excelling in retrieval tasks for low-resource languages.
Ablation Studies
To assess the impact of different training techniques, researchers conducted a series of ablation studies:
- Effect of Pre-Finetuning: Training the model with a pre-finetuning stage showed a 30% improvement over models trained from scratch.
- Synthetic Data Generation: Using LLM-generated synthetic data improved classification and retrieval accuracy by 17.6%.
- Hard Negative Mining: Introducing more challenging negative samples led to a 9% increase in retrieval effectiveness.
Multilingual Performance Analysis
Gemini Embedding demonstrated exceptional cross-lingual retrieval capabilities, significantly outperforming previous models in languages with limited training data. Key findings include:
- Improved performance in 20+ underrepresented languages, including Hindi, Swahili, and Macedonian.
- Enhanced zero-shot learning ability, enabling Gemini Embedding to generalize well across unseen languages.
Conclusion
Gemini Embedding marks a major leap in general-purpose text representations, providing a unified model that surpasses domain-specific embeddings. By leveraging Gemini’s multilingual and code understanding capabilities, it establishes new benchmarks in classification, retrieval, and ranking tasks. The research highlights future possibilities for multimodal embedding expansion, making it a promising direction for NLP advancements.
Would you like further details on a specific experiment or a visual representation of the results?

Unveiling Gemini Embedding: Advancing Generalizable Text Representations