The research paper "What I Cannot Execute, I Do Not Understand: Training and Evaluating LLMs on Program Execution Traces" investigates enhancing large language models' (LLMs) code generation and understanding capabilities by incorporating dynamic execution information during training. Traditional approaches often treat code as static text, overlooking the rich insights obtainable from program execution behaviors.
Key Takeaways:
Execution Tuning (E.T.): A novel training methodology that integrates real-world program execution traces without manual test annotations, improving LLMs' comprehension of code behavior.
Dynamic Scratchpads: An innovative technique where models maintain and update a self-contained representation of intermediate computations, enhancing accuracy in long-execution scenarios.
Improved Output Prediction: Models trained with execution traces achieved approximately 80% accuracy on benchmarks like CruxEval and MBPP, outperforming traditional methods.
Practical Implications: The study suggests that incorporating execution traces can bolster LLMs' performance in tasks requiring deep code understanding, such as debugging and code synthesis.
Overview
Large language models have demonstrated remarkable proficiency in natural language processing and, more recently, in code-related tasks. However, conventional training paradigms often treat code as static sequences of text, neglecting the dynamic nature of program execution.
Code generation and understanding are pivotal capabilities for LLMs, with applications ranging from automated code completion to debugging and maintenance (Brown et al., 2020).
Traditional training datasets for LLMs, such as those used by Chen et al. (2021) and Rozière et al. (2024), typically treat code as static strings. This limitation has sparked interest in modeling program executions to improve code understanding and reasoning capabilities (Zaremba & Sutskever, 2014; Graves et al., 2014).
The static approach limits models' ability to fully grasp the semantics and runtime behaviors of code. The concept of Execution Tuning (E.T.) addresses this limitation by integrating execution traces—records of a program's state changes during execution—into the training process. By exposing models to these dynamic aspects, E.T. aims to enhance their ability to predict program outputs and understand complex code structures.
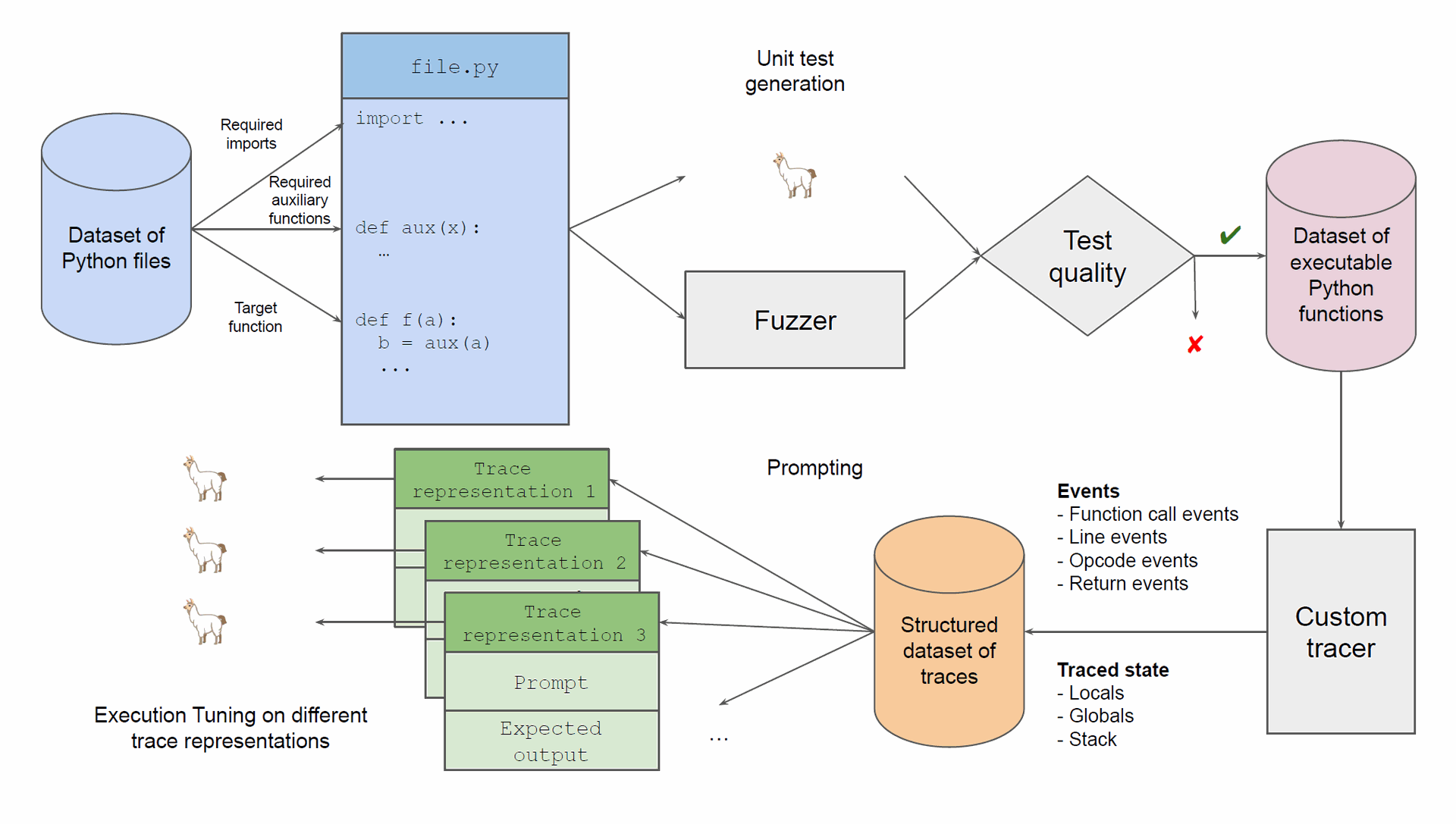
Figure 2: Overview of the data pipeline in E.T. We start from Python functions made executable with synthetic yet representative inputs generated by a combination of LLMs and fuzzing, filtered by test quality. Our custom Python tracer generates a structured dataset of traces. From this dataset, we train models prompted with different trace representations.
Execution Tuning (E.T.)
Execution Tuning (E.T.) is a training procedure that explicitly models real-world program execution traces without requiring manual test annotations. This approach builds on previous work by Nye et al. (2021), who showed that predicting intermediate line-level states of a Python function execution improved output prediction accuracy.
The current study addresses key questions such as increasing the number of examples in trace datasets, the impact of trace granularity on model performance, handling long execution traces, and the effects of trace modeling on downstream code generation tasks.
Why It’s Important
Understanding code execution is pivotal for tasks like debugging, optimization, and accurate code generation. By training LLMs on execution traces, models can develop a more nuanced understanding of program behavior, leading to more reliable and efficient code synthesis.
This approach also holds promise for cross-domain applications, such as enhancing models' reasoning abilities in scenarios where procedural understanding is crucial.
The principles of E.T. can be applied to other domains where dynamic information is crucial.
For example, in natural language processing, dynamic scratchpads could be used to model the evolution of a conversation, improving the accuracy of chatbots and virtual assistants. In robotics, dynamic scratchpads could model the real-time decisions of autonomous systems, enhancing their adaptability and performance.
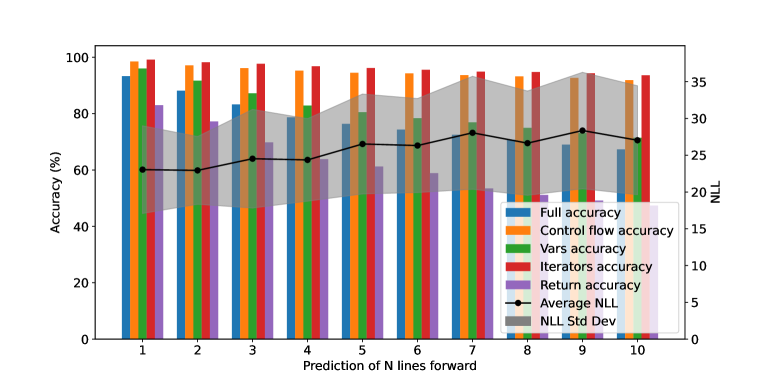
Figure 4: Plot showing individual state prediction accuracy (e.g., for Return, specifically for this plot and unlike in the rest of the article, we mean return statement accuracy, not full execution accuracy) when increasing N lines into the future, compared to the predictions Negative Log-Likelihood. Accuracy (bars) gets lower as the number of steps into the future increases, and confidence decreases as well (i.e., NLL increases).
Experimental Results
The study starts with a collection of 300k Python functions made executable with synthetic inputs generated by LLMs and fuzzing. A custom Python tracer captures local variables, global variables, and additional information obtained from the stack.
We compare three scratchpad strategies for storing the intermediate computations: a) regular scratchpad (Nye et al., 2021), i.e., a dictionary with all the variable values at each step, b) compact scratchpad containing the changed variables only (Ni et al., 2024), and c) dynamic scratchpad (depicted in Figure 1), in which, rather than accumulating all the intermediate computation history, the LLM is asked to update a single, self-contained representation of the current state of the program.
The traces are represented in LLM-friendly formats, including iterators and functions, at different granularities: program, line, and bytecode instructions.
The introduction of dynamic scratchpads allowed models to maintain an updated, self-contained state representation, which proved beneficial in handling long execution sequences, with successful predictions extending up to 14,000 steps.
The study compares three scratchpad strategies for storing intermediate computations: regular scratchpad, compact scratchpad, and dynamic scratchpad.
On benchmarks like CruxEval and MBPP, models trained with execution traces achieved around 80% accuracy, showcasing a significant improvement over models trained without such dynamic information.
Particularly, we select functions in the MBPP test set with nested loops (as a proxy of computational complexity and execution length), leaving us with slightly fewer than 100 functions.
The evaluation on the MBPP dataset and algorithmic tasks with long executions shows that instruction-based models perform better on longer executions.
The dynamic scratchpad models demonstrate the ability to handle long executions effectively, with Line-n models achieving high accuracy with fewer steps. The study also highlights the potential of dynamically skipping steps to decrease the number of intermediate steps required.
Conclusion
Incorporating program execution traces into the training of large language models offers a substantial enhancement in their ability to understand and generate code.
The Execution Tuning methodology, coupled with dynamic scratchpads, provides a framework for developing models that more closely emulate the cognitive processes of human programmers, leading to more accurate and reliable code-related task performance.

Training and Evaluating LLMs on Program Execution Traces