Today we take a look at some research straight out of Mission Impossible! The ability to recover sound from surfaces and objects. The new method suggests higher fidelity recovery is possible from potato chip bags to windows.
This research out of China introduces a novel deep learning-based pipeline called EvMic for non-contact sound recovery from object vibrations captured by an event camera. The proposed method leverages the high temporal resolution of event cameras and incorporates effective spatial-temporal modeling to overcome the limitations of traditional frame-based approaches in recovering sound from subtle, high-frequency vibrations.
Key Takeaways
- The study presents EvMic, the first deep learning-based system for non-contact sound recovery using event cameras, demonstrating superior performance compared to existing frame-based methods.
- A new synthetic dataset, EvMic, was created using Blender and an event simulator to train the network, addressing the challenge of obtaining ground truth data for this task.
- The proposed network architecture effectively utilizes the sparsity of event data with sparse convolutions, models long-term temporal dependencies with Mamba, and aggregates spatial information with a novel spatial aggregation block (SAB).
- Experiments on both synthetic and real-world data show that EvMic achieves higher signal-to-noise ratio (SNR) and speech intelligibility (STOI) compared to baseline methods and exhibits robustness to varying vibration directions and the ability to capture sound from a large field of view.
- The use of sparse convolutions significantly reduces the computational load and memory usage of the model.
- The research highlights the potential of event cameras for advancing non-contact sound recovery and opens avenues for future work in refining acquisition systems and incorporating prior knowledge.
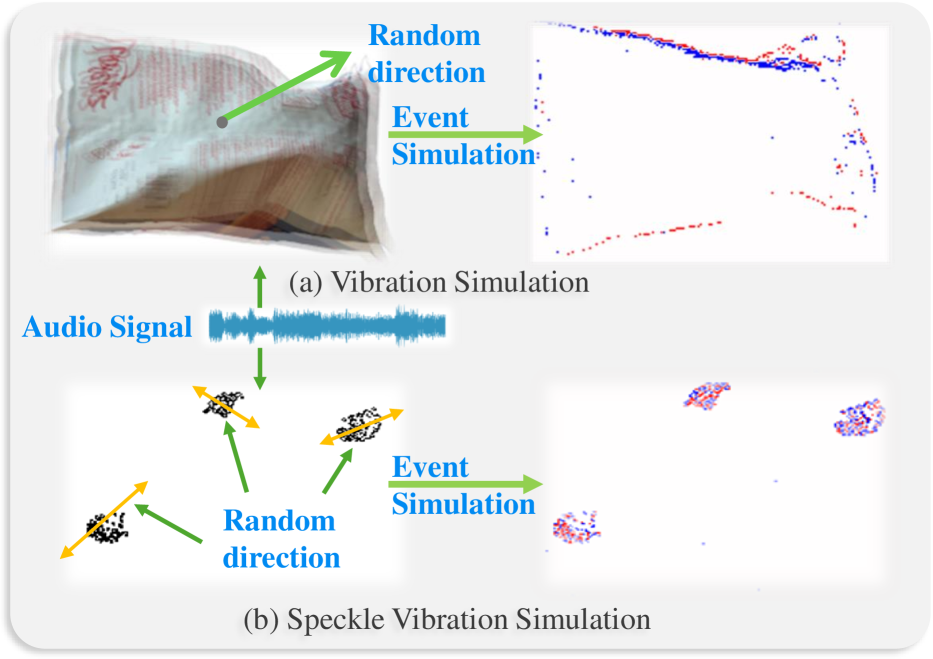
Figure 2:(a) Our data simulation starts with controlling the objects’ vibration. We utilize audio to manipulate the coordinates of objects resulting in their vibrations across random directions. Then we use an event simulator to generate the corresponding events. The generated events are used for training. (b) The synthetic vibrating speckles are used for fine-tuning and testing.
Overview
Non-contact sound recovery is a technique that aims to reconstruct sound by analyzing the subtle vibrations of objects caused by sound waves, with applications in areas like surveillance and material property analysis.
Traditional approaches often rely on high-speed frame-based cameras to capture these vibrations. However, frame-based cameras face inherent trade-offs between sampling rate, bandwidth, and field of view, making it challenging to recover high-frequency sounds from minute vibrations.
For instance, increasing the sampling rate often leads to a narrower field of view. Laser Doppler velocimeters (LDVs) offer high precision but can only measure vibrations at a single point and have complex optical paths.
While methods using speckle patterns or phase-based signal processing with frame-based cameras have been explored, they remain limited by the sensor's capabilities.
Event cameras
Event cameras present a promising alternative due to their unique asynchronous operation, which allows them to capture brightness changes at each pixel independently with very high temporal resolution, typically in the order of microseconds, and without motion blur.
Unlike frame-based cameras that capture intensity at a fixed rate across the entire sensor, event cameras only output "events" when a significant change in logarithmic brightness occurs. This sparsity enables them to handle high-frequency signals and cover a large field of view while reducing data redundancy.
The researchers in this paper propose a novel pipeline, EvMic, that fully exploits the spatial-temporal information from event streams for non-contact sound recovery.
As illustrated in Figure 1, EvMic utilizes a laser matrix to enhance the gradient of the object's surface, making the subtle vibrations more detectable by the event camera, effectively converting the vibrations to more pronounced light intensity changes that can be detected by the event camera.
The event camera captures a temporally dense stream of events reflecting these vibrations. EvMic then employs a learning-based approach with a specifically designed neural network to recover the sound signal from this event stream.
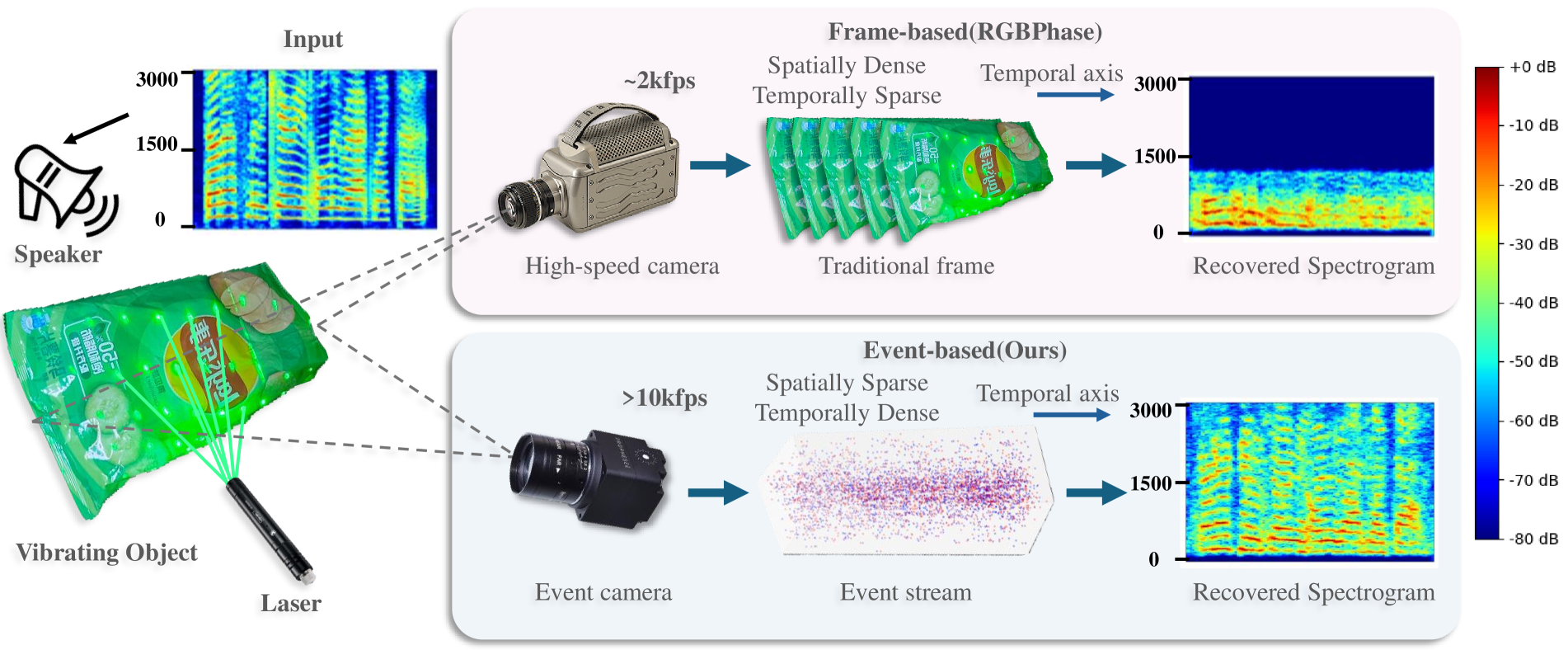
Figure 1:Illustration of our event-based non-contact sound recovery. We try to recover sound from the visual vibration of the object caused by the sound wave. Compared with the traditional high-speed camera solution (top), we proposed to use an event camera to capture a temporally dense signal (bottom). We first utilize a laser matrix (left) to amplify the gradient and an event camera to capture the vibrations. Then, our learning-based approach to spatial-temporal modeling enables us to recover better signals.
To train their deep learning model, the authors created EvMic, the first synthetic dataset for event-based non-contact sound recovery. This dataset consists of approximately 10,000 segments of data generated using Blender for realistic visual effects and an event simulator (V2E) to produce corresponding event streams based on audio-driven object vibrations.
To improve the model's generalization to real-world scenarios, supplementary synthetic data with vibrating speckles was also created and used for fine-tuning.
The proposed network architecture (shown in Figure 3a) consists of three main components: a lightweight visual feature extraction module based on sparse convolutions, a spatial aggregation block (SAB) utilizing multi-head self-attention, and a temporal modeling module employing the Mamba structured state space model.
- The sparse convolutional backbone efficiently extracts features from the sparse event data.
- The SAB adaptively aggregates information from different spatial locations (specifically, patches centered on laser speckles) to improve the signal-to-noise ratio, considering the varying vibration directions caused by the object's surface geometry.
- The Mamba model excels at capturing long-term temporal dependencies in the extracted features, which is crucial for reconstructing coherent audio signals.
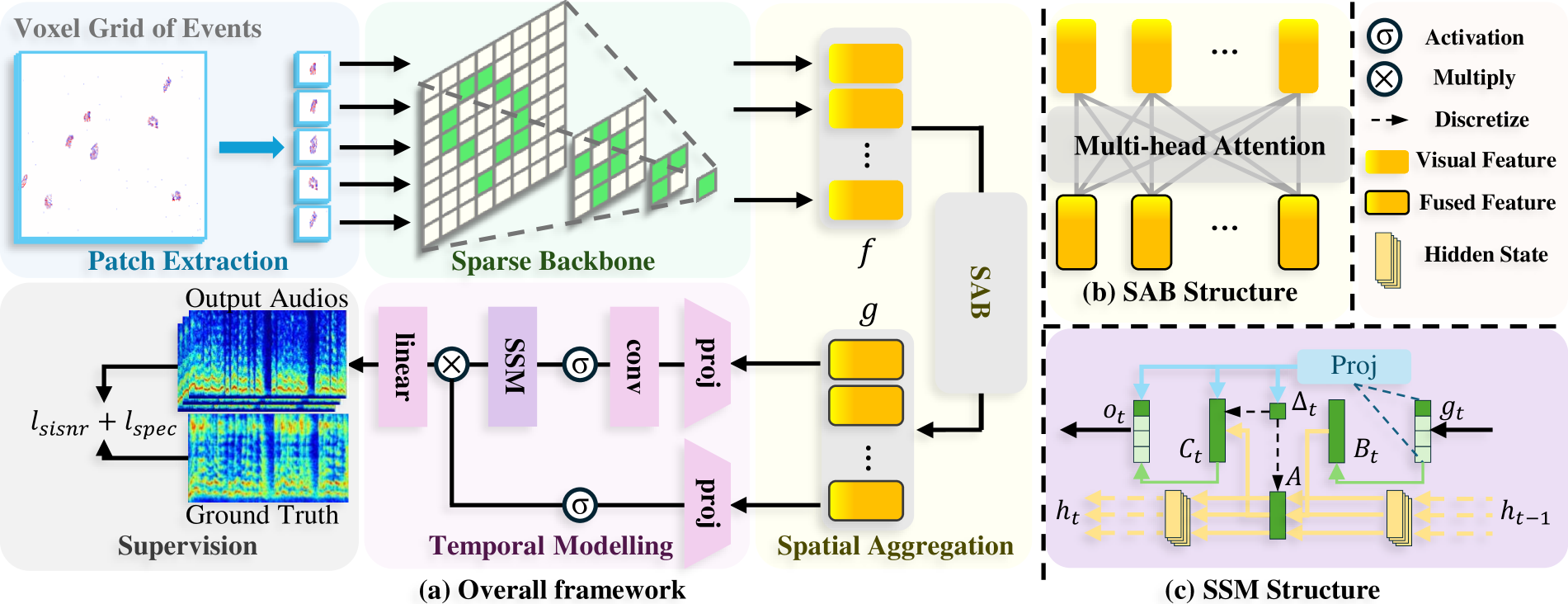
Figure 3: (a) Overview of our proposed network architecture. The event stream is processed into voxel grids, from which patches centered around the speckles are selected. First, the patches are input into a sparse convolution-based lightweight backbone to extract visual features. Next, a spatial attention block aggregates the information in the different patches. Finally, Mamba is employed to model long-term temporal information and reconstruct the audio that caused the object’s vibration. (b) and (c) illustrate the detailed structure of SAB and SSM. (c) At time t gt is the input feature, ot is the output and ht denotes the hidden state. A, B, and C are the gating weights optimized by Mamba. ∆ is used to discretize the continuous parameters A and B.
Why it’s Important
The ability to recover sound without physical contact has significant implications across various fields.
In engineering, it could be used for non-destructive testing and structural health monitoring by analyzing the acoustic response of materials to induced vibrations.
In scientific research, it can aid in studying the physical properties of materials and understanding acoustic phenomena.
Furthermore, in surveillance and security applications, non-contact sound recovery could provide a means to extract audio information from a distance without being intrusive.
The EvMic system addresses the limitations of existing visual sound recovery techniques by leveraging the unique advantages of event cameras and machine learning.
Compared to frame-based methods, it offers a higher temporal resolution and a potentially larger field of view without sacrificing one for the other.
The use of a laser matrix simplifies the optical path compared to some laser-based vibration measurement techniques while enhancing the signal amplitude captured by the event camera.
The authors also demonstrated robustness to varying vibration directions marking a significant advantage over frame based techniques, as real-world objects vibrate in complex ways.
The introduction of a deep learning-based approach allows for the effective modeling of complex spatial-temporal relationships in the event data, leading to improved sound recovery quality compared to traditional signal processing methods applied to event streams.
Finally the creation of the EvMic synthetic dataset is a crucial contribution, as it provides a valuable resource for training and evaluating event-based sound recovery algorithms, a task that is challenging to do with real-world paired data due to issues like alignment and reverberation.
As the training data is improved it is conceivable that the performance will be considerably improved, however as the authors note, challenges remain in acquiring sufficient real world training data.
Summary of Results
The researchers conducted extensive experiments on both synthetic and real-world data to evaluate the performance of their proposed EvMic method.
For synthetic data, they compared EvMic against two baseline methods:
- RGBPhase, a state-of-the-art frame-based approach
- EvPhase, an existing event-based phase estimation method
The synthetic data was generated using audio samples from the TIMIT dataset, with high-frame-rate videos (10,000 FPS) simulated and then converted to event streams using V2E (an event simulator that takes video frames as input and outputs realistic event data).
The RGB method used downsampled videos (2,500 FPS). Performance was evaluated using Signal-to-Noise Ratio (SNR) and Speech Intelligibility (STOI).
Table 1 shows the quantitative comparison results on synthetic data, demonstrating that Ours(8kHz) (EvMic) outperformed both RGBPhase and EvPhase across different synthetic sequences in terms of both SNR and STOI.
For instance, EvMic achieved an average SNR (Signal to Noise Ratio) of 1.214 dB and an average STOI (Speech Intelligibility) of 0.481, representing a significant improvement over the baselines.
RGBPhase suffered from its limited sampling rate, while EvPhase struggled with fixed filter parameters when faced with varying vibration directions.
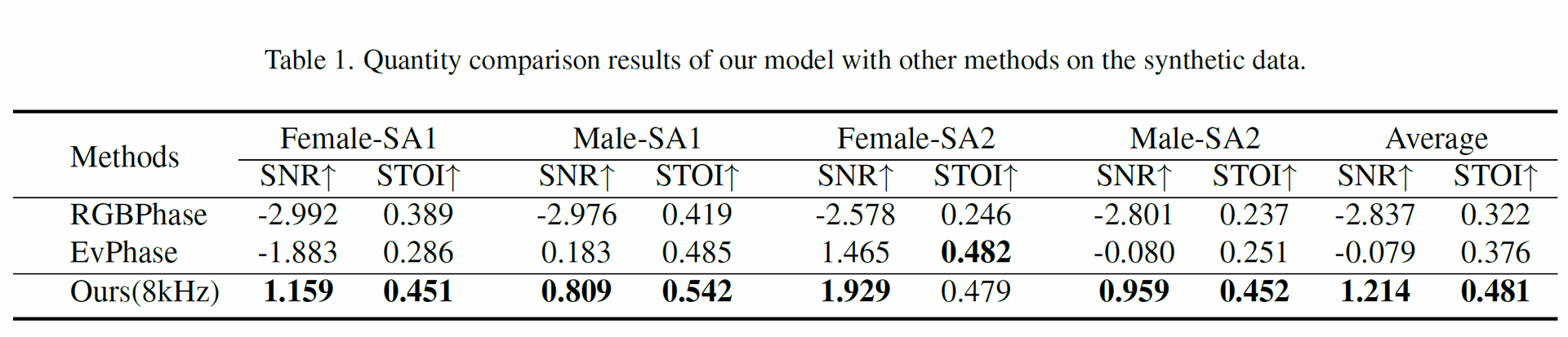
Table 1: Quantity comparison results of our model with other methods on the synthetic data.
For real-world evaluation, the authors captured several sequences using a Prophesee EVK4 event camera with a laser matrix. They evaluated different setups, including a chip bag and a speaker driven by speech and MIDI audio. Reference audio signals were recorded using a microphone.
Figures 4 and 5 show spectrograms of the recovered sound from the chip bag and speaker, respectively, along with the corresponding microphone recordings.
The qualitative results indicate that EvMic's recovered audio more closely matches the fundamental frequencies and harmonics of the microphone recordings compared to EvPhase, which tended to amplify high-frequency components.
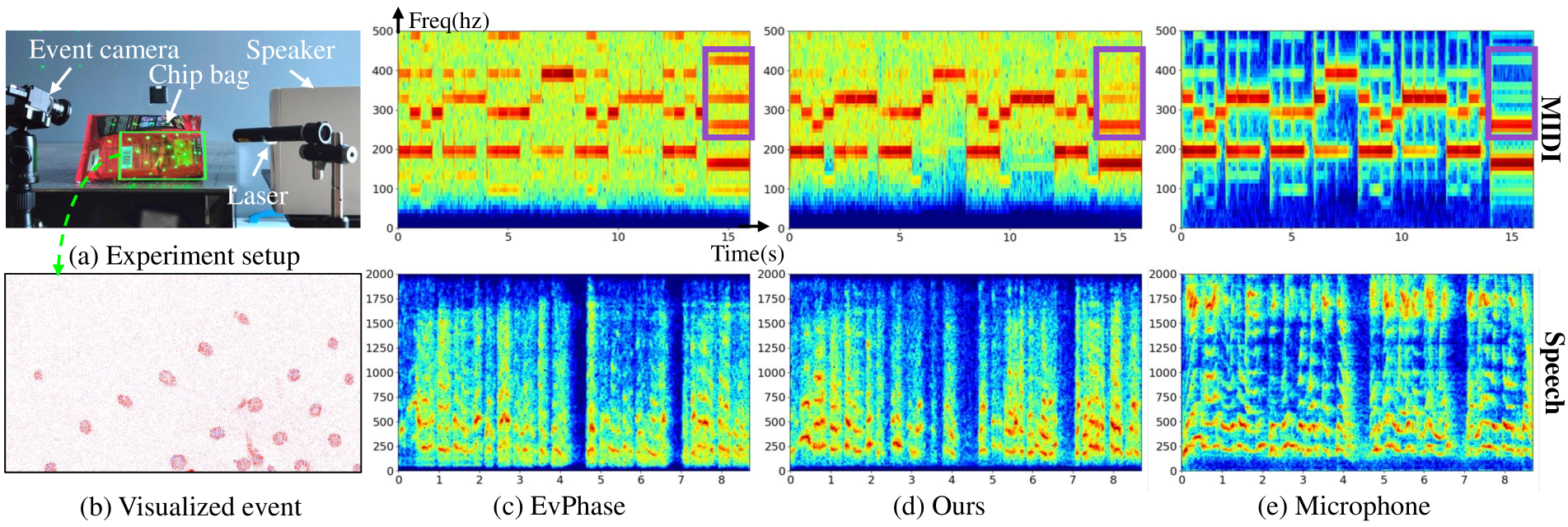
Figure 4: Qualitative comparison results on the real-world data of a chipbag. Audio is provided in the supplementary.
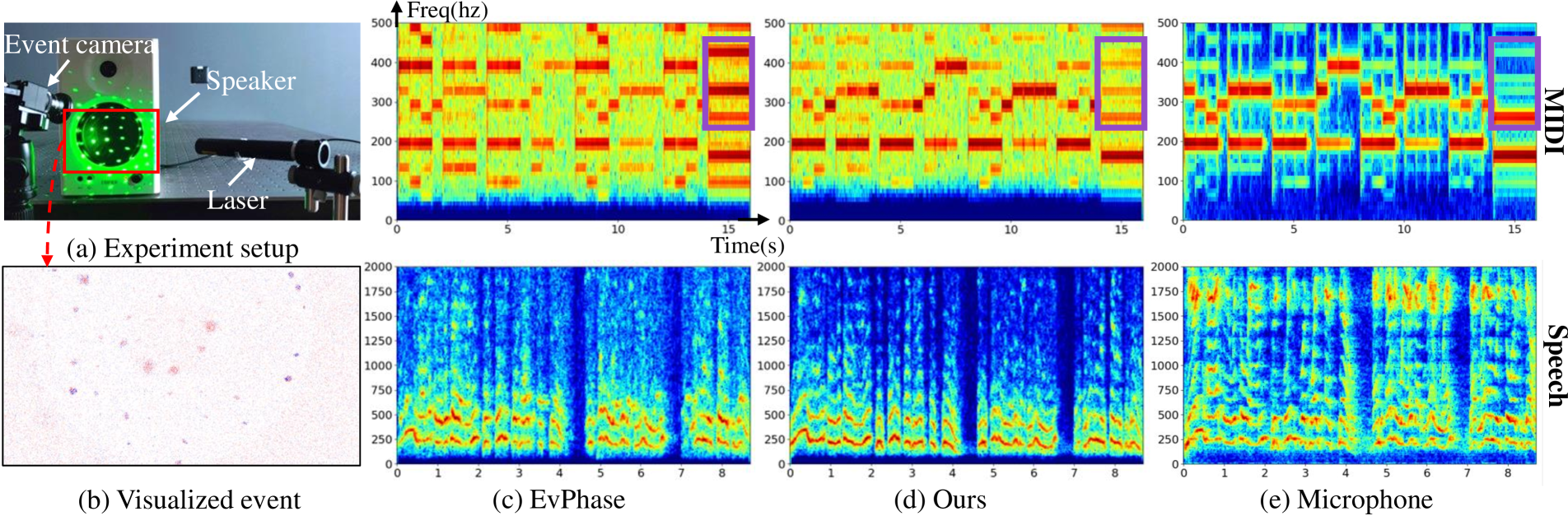
Figure 5: Qualitative comparison results on the real-world data of a speaker. Audio is provided in the supplementary.
The research also demonstrated the system's ability to handle a large field of view by recovering sound from glitter papers at various positions and even separating stereo audio sources using multiple speakers (as shown in Figure 6).
Figure 7 illustrates the robustness of EvMic to different vibration directions compared to EvPhase, which is sensitive to the spatial orientation of its filter.
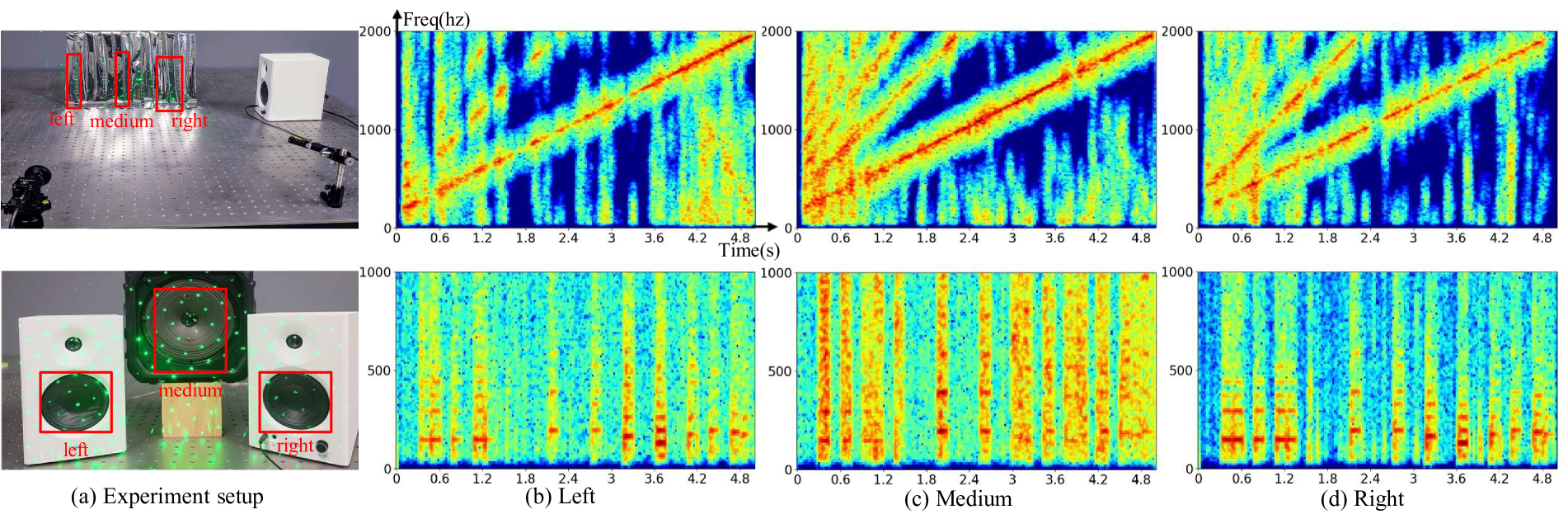
Figure 6: Capture objects from a distance to obtain a large field of view. Top: Capture glitter papers while playing chirp audio. Bottom: Capture multiple speakers to recover stereo audio. The left and right speakers play left and right channels respectively, while the medium speaker plays a mixed mono channel. Audio is provided in the supplementary.
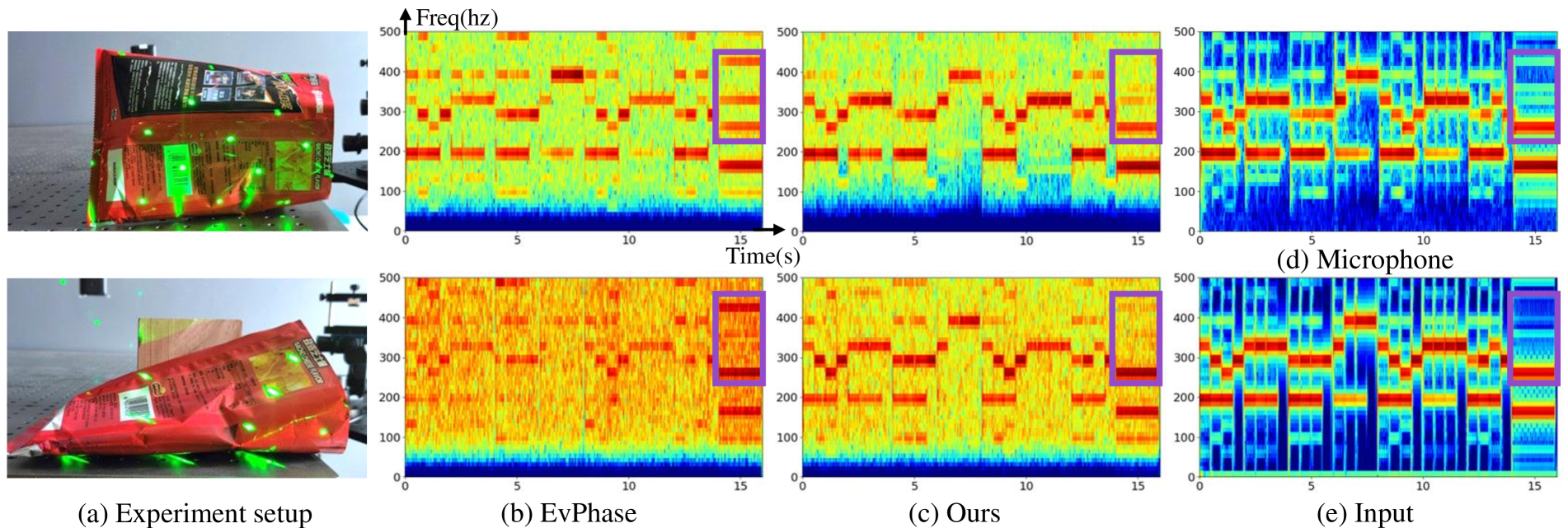
Figure 7: Ablation analysis for different vibration direction. The object is placed in different orientations to produce various vibration directions. Audio is provided in the supplementary.
Conclusion
This research successfully presented EvMic, the first deep learning-based pipeline for non-contact sound recovery using event cameras.
By effectively modeling the spatial-temporal information inherent in event streams through a novel network architecture incorporating sparse convolutions, a spatial aggregation block, and the Mamba temporal model, EvMic achieved state-of-the-art performance on both synthetic and real-world datasets.
The creation of the EvMic synthetic dataset is a significant contribution to the field. While acknowledging limitations related to the gap between synthetic and real event data and the influence of laser power and lighting conditions, this work convincingly demonstrates the potential of event cameras for advancing non-contact sound recovery and lays the groundwork for future research focused on refining data acquisition and incorporating generative prior knowledge.


SpyCraft: Non-Contact Sound Recovery with Event Cameras and Deep Learning
EvMic: Event-based Non-contact Sound Recovery from Effective Spatial-temporal Modeling