There are significant challenges in LLMs to produce accurate information retrieval and reasoning for very long inputs such as textbooks and research papers. Popular LLMs suffer from hallucinations and much lower retrieval accuracy as the input length increases.
Previous approaches attempt to remedy the issue by increasing the context window or truncating the input through process such as Retrieval-Augmented Generation (RAG). However both these solutions have suboptimal results for long inputs.
Introducing Chain of Agents
Chain of Agents is a novel approach to long context reasoning and information retrieval. Researchers at Penn State and Google AI Research propose a way of organizing LLM agents to collaborate on the content by breaking it down into multiple workers and a manger to process the result. The process leverages multi-agent collaboration to enable effective information aggregation and context reasoning across various LLMs for long-context tasks.
The new agent design is model and context length agnostic. To achieve top of class performance the content is segmented into chunks that fit within the context window of the LLM being used. It then spawns multiple agents (Workers) of the base LLM to collaborate on a response to the user query which is reviewed by a manager who crafts a final answer. The agents communicate through "Communication Units" allowing them to pass information to other Workers and finally reviewed by the Manager.
CoA leverages the capability of communication rather than trying to feed many tokens into an LLM.
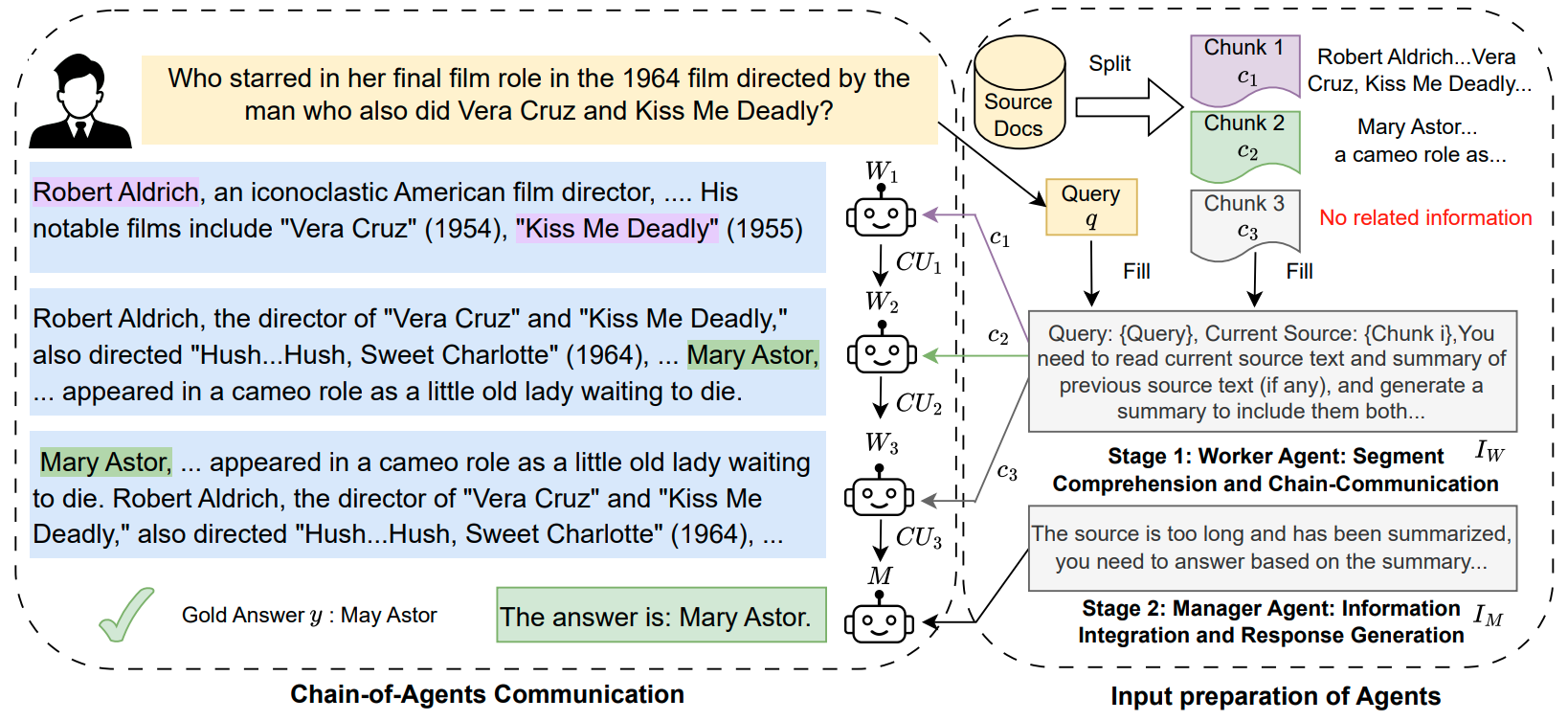
Chain of Agents Process Outline. Figure 1 of Paper.
Figure 1: Overview of Chain-of-Agents, a training-free, task agnostic, and highly-interpretable framework that harnesses multi-agent collaboration for long-context tasks. Blue boxes indicate communication unit CUi between worker agents Wi and Wi+1. It consists of multiple worker agents who sequentially communicate to handle different segmented portions of the text, followed by a manager agent who synthesizes these contributions into a coherent final output.
Other Long Context Processes
The authors compare the performance of CoA with popular techniques for handling long context tasks. The other techniques included RAG and Vanilla explained briefly below.
Retrieval-Augmented Generation (RAG)
RAG combines retrieval mechanisms with generation capabilities. It retrieves the most relevant chunks of information from a large corpus using embedding similarity and then feeds these chunks into a language model for generating responses.
By retrieving only the most relevant parts of the input, RAG reduces (truncates) the input length that the language model needs to process. This helps in managing long contexts by focusing on the most pertinent information. However, it may miss out on important information if the retrieval accuracy is low or there is misinformation.
Vanilla
The Vanilla approach directly feeds as many tokens as possible into the language model until the context window limit is reached. This process assumes that the context window of the LLM can be utilized accurately, something we can see from the experimental results is not the case.
Vanilla attempts to handle long contexts by utilizing the maximum context window of the language model. This means it processes the input sequentially until the window is full. However, it can struggle with focusing on the necessary information, especially when the context is very long, leading to issues like the "lost in the middle" phenomenon.
How Does CoA Compare to RAG and Vanilla
The authors compare the performance of Chain of Agents against Vanilla and RAG processing methods on popular summarization, reasoning and coding benchmark data sets. The results show that the Chain of Agents reasoning is superior to the other techniques for the 8k context length. The CoA method shows increased performance for content longer than the LLMs context window. Bison and unicorn both have context windows of 8k tokens while Gemini Ultra has a 32k input length.
The most interesting result is how CoA compares to the Gemini Ultra model which when compared to Vanilla process for 8k input length significantly better on most data sets. The Gemini model claims 32k input length which assumes it will be able to retrieve and reason through a large input. However what we see is degraded performance compared to the multi agent process and in some cases vs the RAG implementation.
Further investigation into the Claude long window LLMs shows that CoA significantly outperforms Claude 3 even with a 200k context limit when the input length is smaller and larger than the LLM window. (Table 5)
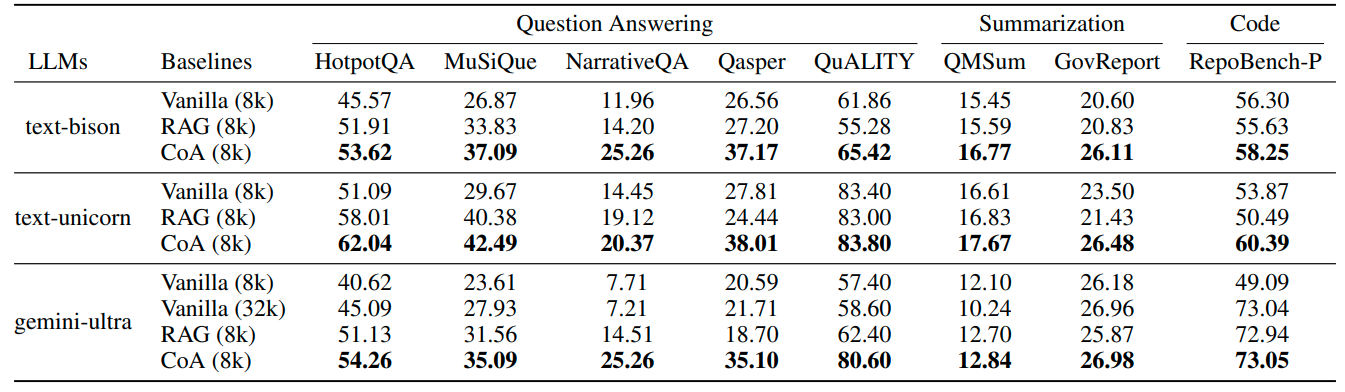
Overall results of CoA. CoA significantly outperforms Vanilla and RAG using various backbone LLMs on all datasets. Table 4: (updated with relative percentage improvement.)
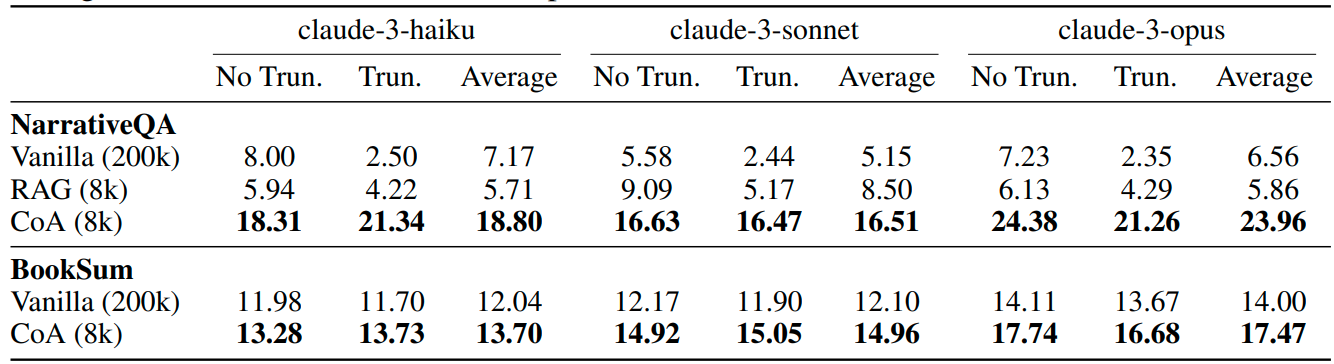
Table 5 updated to relative percentage increases: Comparison with long context LLMs on NarrativeQA and BookSum. CoA significantly outperforms Claude 3 with 200k context limits. No Trun./Trun. indicates the source text in the sample is less/more than 200k tokens which does not need/needs truncation for vanilla (200k) baseline. Average is the mean value across all samples.
Overview of the Benchmark Datasets
To understand the results of the table below we need a little background on the data sets being used in the report. These data sets provide different insights into the potential uses and performance of chain of agents, RAG and Vanilla context processing.
HotpotQA: A Wikipedia-based multi-hop question answering dataset. Requires reasoning across multiple passages to find the answer.
MuSiQue: A multi-hop question answering dataset. More challenging than HotpotQA, containing more hops in one sample, unanswerable questions, and harder distracting content.
NarrativeQA: A question answering dataset over entire books or movie transcripts. The answers can be abstract or extractive, yes/no, and unanswerable.
Qasper: A question answering dataset over NLP research papers. Contains extractive, abstractive, yes/no, and unanswerable questions.
QuALITY: A dataset based on stories and articles with multiple-choice questions for each sample. The model needs to select the correct answer among choices.
QMSum: A query-based summarization dataset formed by meeting transcripts from multiple domains such as academic and industrial products. Summarization based on specific queries.
GovReport: A generic summarization dataset containing long reports published by the U.S. Government Accountability Office. Summarization of long government reports.
RepoBench-P: Collected from GitHub repositories. The model needs to generate the next line of code given the long code base.
Performance on Large Input vs Full Context
The performance of CoA is obvious for large input lengths. The below table illustrates how the CoA handles full input above 400k tokens exceptionally better than Claude using the full context can.
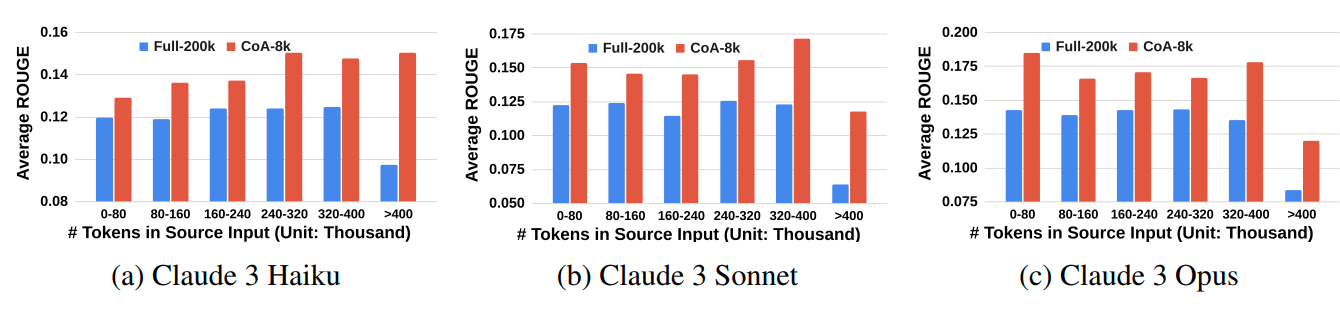
Figure 2. CoA vs Fill context input for varying input lengths. The CoA shows dramatic improvement for inputs longer than the context window of the LLM (Claude 3 has a 200k token window).
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics used for evaluating automatic summarization and machine translation. It compares the overlap of n-grams (typically unigrams, bigrams, and longer n-grams), word sequences, and word pairs between the machine-generated summary or translation and a set of reference summaries or translations.
Average ROUGE score is used to evaluate the quality of summarization tasks, indicating how well the generated summaries match the reference summaries.
The most commonly used ROUGE metrics are:
- ROUGE-N: Measures the overlap of n-grams between the system and reference summaries. For example, ROUGE-1 refers to the overlap of unigrams, ROUGE-2 to the overlap of bigrams, etc.
- ROUGE-L: Measures the longest common subsequence (LCS) between the system and reference summaries, which takes into account sentence-level structure similarity.
- ROUGE-W: A weighted version of ROUGE-L that gives more importance to longer subsequences.
- ROUGE-S: Measures the overlap of skip-bigrams, which are pairs of words in their sentence order, allowing for gaps.
ROUGE scores are typically reported as recall, precision, and F1-score:
- Recall: Measures how much of the reference summary is captured by the generated summary.
- Precision: Measures how much of the generated summary is relevant to the reference summary.
- F1-score: The harmonic mean of recall and precision, providing a single score that balances both.
Conclusion
The paper illustrates that by finding novel ways for LLMs to interact with themselves we can create more powerful agents for long inputs. While the limitations include efficiency and cost compared to current processes, the significant increase in retrieval accuracy and reasoning over large context is a suitable trade off.
CoA improves on previous methods including other multi agent frameworks. The author's conclude:
- CoA Improvement is More Obvious When RAG Fails to Retrieve Gold Answer
- CoA Improvement is More Obvious When Long Context Models Meet Longer Inputs
- CoA Mitigates “Lost-in-the-Middle” Phenomenon
- Multi-agent Collaboration in CoA Enables Complex Reasoning over Long Context
- Multi-path Chain-of-Agents Further Enhances Performance
The authors note the limitations include the need for improved communication effectiveness via finetuning or in-context learning, exploration of other communication approaches like debating, and reduction of cost and latency through more effective models.
The introduction of Chain of Agents offers the development community a new way to get the most out of LLMs without pre-training or other model modifications. This allows us to leverage current generation models for improved reasoning across a large input length potentially opening up new areas of research, collaboration and insights into content that previously suffered from poor processing performance. The simple nature of the implementation means that many users can benefit from similar implementation right away. I look forward to seeing how this technology empowers us to build more!

Penn State & Google Research Propose Chain of Agents: Model and Length Agnostic Query Processing
Chain of Agents: Large Language Models Collaborating on Long-Context Tasks