Generative Artificial Intelligence (AI) models, particularly large language models (LLMs), have significantly altered the landscape of natural language processing and hold immense potential for scientific advancement.
However, applying these models to complex technical fields like biomateriomics, which requires drawing insights from diverse, multiscale knowledge, presents unique challenges. Traditional LLMs often rely on single-pass reasoning and struggle with reflecting on or iterating over complex tasks, a capability often limited to only very large "frontier" models.
To overcome these limitations and enable LLMs to perform more sophisticated scientific reasoning, researchers have introduced PRefLexOR (Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning). This novel framework integrates preference optimization with reinforcement learning (RL) concepts to create a self-improving system for scientific reasoning.
This innovative framework is designed to enable artificial intelligence models to self-improve their scientific reasoning and agentic thinking capabilities. PRefLexOR employs a recursive approach, refining its thought processes much like a human scientist would, to tackle complex, open-domain problems, even with relatively small AI models.
Key Takeaways
- Recursive Approach: PRefLexOR refines intermediate steps before generating final outputs during both training and inference, enabling a deeper level of reasoning.
- Preference Optimization: It optimizes the difference between preferred (correct/well-reasoned) and non-preferred (incorrect/poorly-reasoned) responses, enhanced by techniques like rejection sampling.
- In-Situ Dataset Generation: The framework autonomously generates synthetic preference data during the recursive reasoning process, addressing challenges in obtaining human preference data for complex multi-step reasoning.
- Dynamic Knowledge Graph: The system uses an in-situ dataset generation algorithm, optimizing the log odds between preferred and non-preferred responses, and contextualizes reasoning with a dynamic knowledge graph built using retrieval-augmented data. This mirrors biological adaptation, facilitating real-time learning.
- Effectiveness with Small Models: The research found that even small models (3B parameters) trained with PRefLexOR can self-teach deeper reasoning and effectively solve open-domain problems.
- Enhanced Reasoning Depth: Through recursive optimization guided by feedback loops (mirroring biological adaptation), the model refines its reasoning pathways.
- Cross-Domain Adaptability: PRefLexOR demonstrates the ability to apply learned reasoning strategies to tasks outside its primary training domain and make connections between seemingly disparate fields.
- Integration: The method can be integrated into existing LLMs and larger agentic systems.
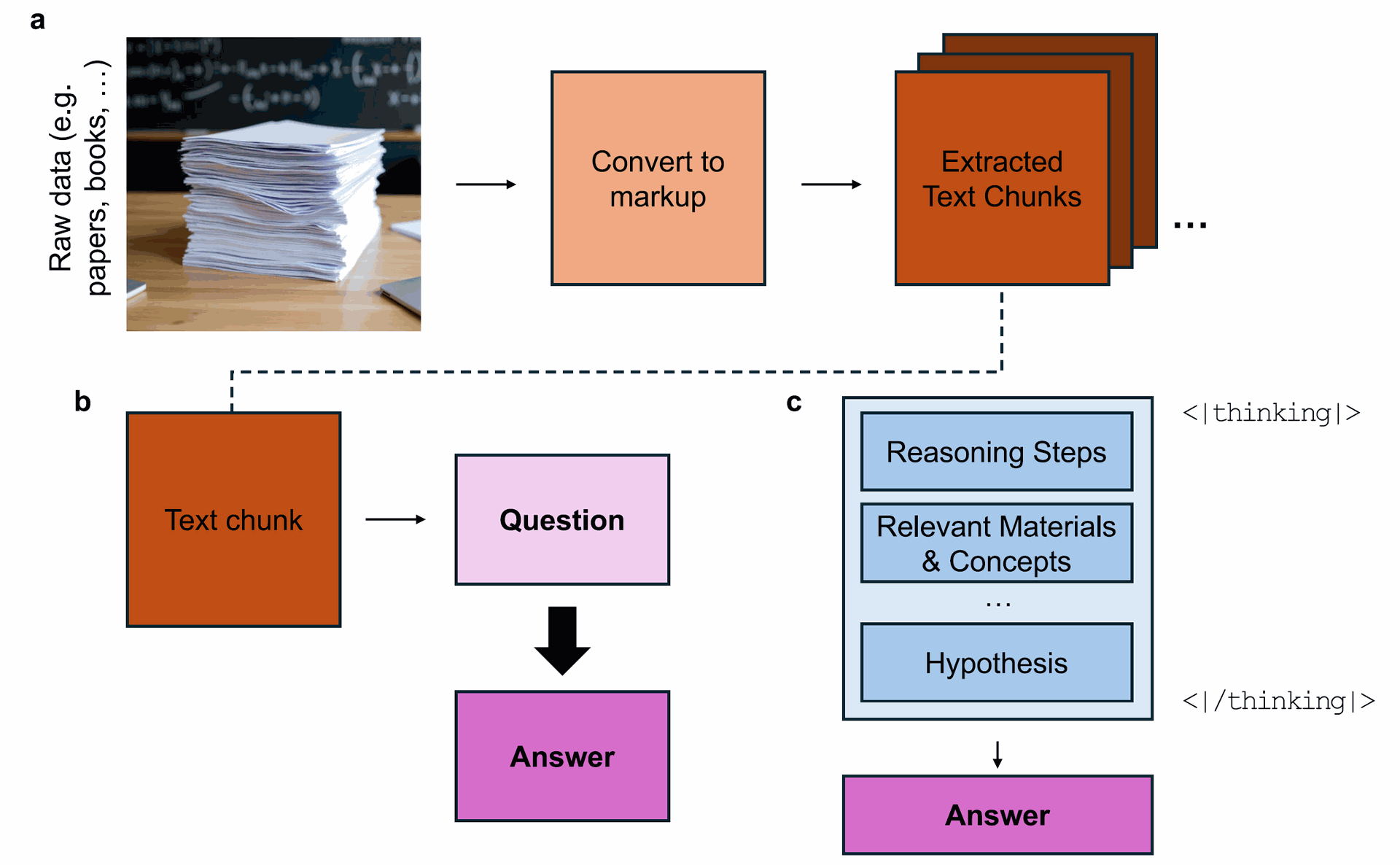
Fig. 2 | Strategic dataset generation process with structured thought integration. This figure illustrates a novel approach to generating datasets, where random text chunks are selected from raw data sources (e.g., papers, books, documents, notes, etc.) and used to develop question-answer pairs in a structured and strategic manner.
Overview
PRefLexOR is presented as a framework designed to imbue generative AI models with more sophisticated scientific reasoning capabilities, moving beyond conventional single-step predictions towards models with greater situational awareness, self-reflection, error correction, and exploration of novel solutions.
The core idea is to integrate preference optimization, a method where a model learns by distinguishing between better and worse responses, with reinforcement learning (RL) concepts.
In RL, an agent learns to make decisions by performing actions in an environment to achieve a goal, receiving feedback (rewards or penalties) for those actions. PRefLexOR enables models to self-teach by iterating over thought processes and learning from preferred and rejected outputs, akin to policy refinement in RL.
This approach is combined with a recursive strategy where the model iteratively refines its thinking and intermediate steps before arriving at a final answer. This process is inspired by biological adaptation, enabling real-time learning and continuous refinement.
A key component is the in-situ dataset generation algorithm. Instead of relying solely on static, pre-collected data, PRefLexOR generates synthetic preference data autonomously within its recursive reasoning loops. This is crucial for training models on multi-step reasoning tasks, where collecting reliable human preference data is complex and costly.
PRefLexOR also utilizes a dynamic knowledge graph, which evolves as the model reasons. This graph is built using Retrieval-Augmented Generation (RAG), where the model queries a corpus (like scientific papers) to retrieve and integrate contextually relevant information, contextualizing its reasoning.
The interaction between generated questions and retrieved data forms a graph where text chunks are nodes and their relationships are edges, facilitated by an embedding model that maps similar information to adjacent nodes. The embedding model used in the RAG process described is BAAI/bge-large-en-v1.5.
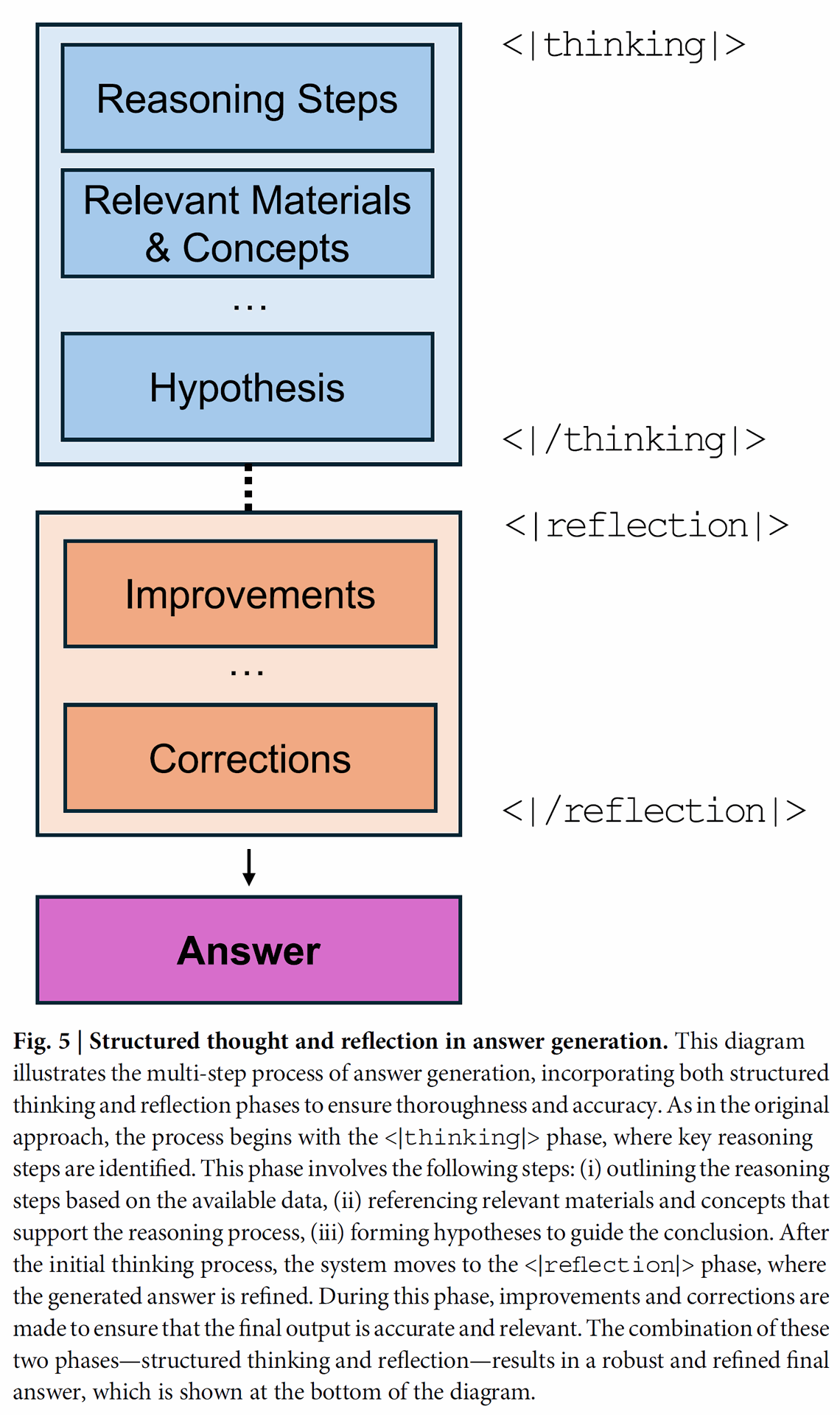
The system uses special tokens like <thinking|> and <reflection|> to explicitly guide the model through phases of reasoning and self-critique. This structured approach helps the model to organize its "thoughts" and improve upon them.
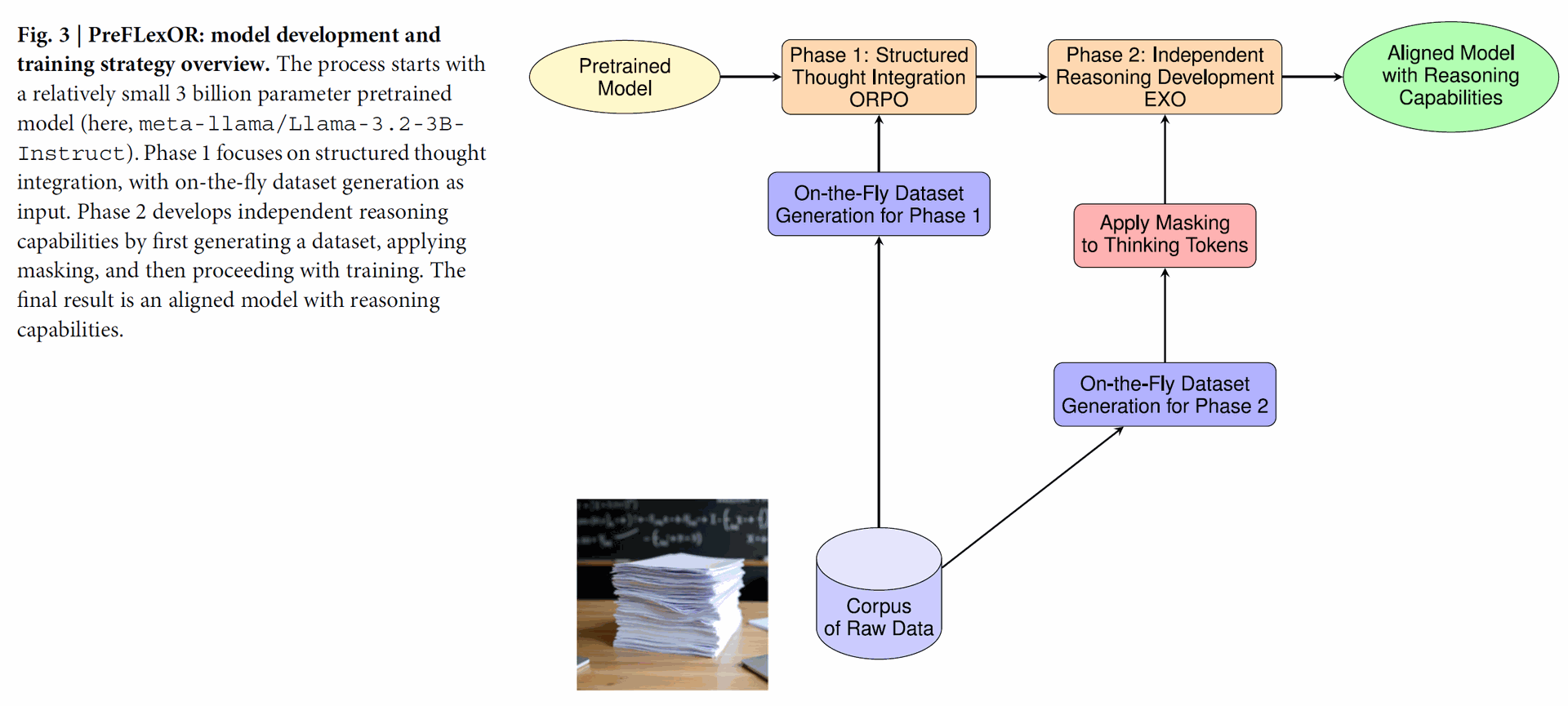
Two-Phase Training: Training involves:
- Structured Thought Integration: Teaching the model to use reasoning tokens and align with high-quality, step-by-step reasoning using Odds Ratio Preference Optimization (ORPO).
- Independent Reasoning Development: Masking intermediate "thinking" steps and using Efficient Exact Optimization (EXO) to force the model to develop its own reasoning strategies to arrive at correct final answers.
This training improves performance in reasoning tasks and deepens the model's ability to make decisions without explicit guidance.
Domain-specific question-answer data is generated dynamically using an agentic framework to provide structured thinking mechanisms. This includes extracting structured information categorized into areas like reasoning steps, relevant materials, and design principles.
This information forms a "Thinking Section for Reasoning". An incorrect answer is also generated, which is later refined during preference-based alignment by feeding the trained model's current incorrect answer back into the generation process, challenging the model to develop better reasoning.
Figure 1 illustrates the shift in generative materials informatics from conventional single-step predictions (Fig. 1b) to the PRefLexOR approach (Fig. 1c), which uses explicit "thinking" and "reflection" via iterative reasoning, contextual understanding, self-assessment, and self-learning, inspired by RL and biological paradigms.
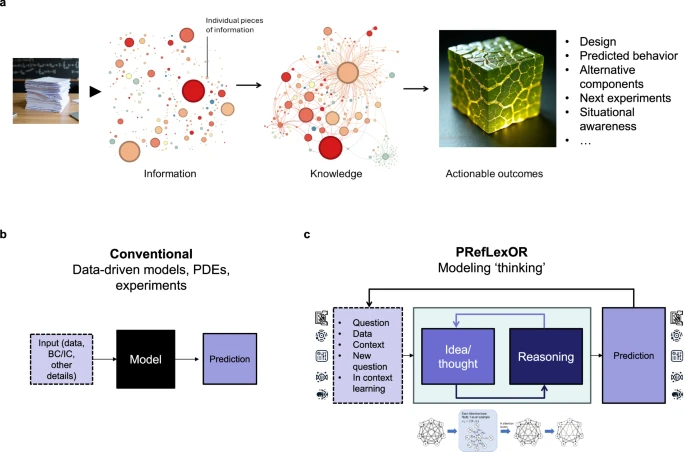
Fig. 1 | Illustration of the workflow and design principles behind generative materials informatics. a The process of transforming information into knowledge and actionable outcomes. Each individual piece of information (left) is synthesized into a network of interconnected knowledge, leading to informed decisions and innovative designs (right). b Conventional approaches in materials science rely on data-driven models, partial differential equations (PDEs), and experimental results, focusing on single-step predictions. c In contrast, generative materials informatics models built on the PRefLexOR framework proposed in this paper use “thinking” and “reflection” explicitly by incorporating iterative reasoning and contextual understanding, allowing for more complex,multi-step predictions.This approach expands from single inference steps, includes multiple modalities of data and responses, integrates real-world feedback and physics, and leverages self-assessment and self-learning.Using reinforcement learning (RL) principles, the discovery of principles or the solution of specific tasks is further inspired by biological paradigms, using bio-inspired neural network designs. These advanced methods support continuous improvement in material predictions, enabling more adaptable and intelligent designs.
Why it’s Important
The PRefLexOR framework is important because it tackles key limitations of current LLMs in performing complex scientific tasks and opens new avenues for AI in scientific discovery.
- Moving Beyond Single-Pass Reasoning: Conventional AI systems often use a single-pass approach, generating output without reflecting on the steps, which is inadequate for multi-step or open-domain problems requiring deeper reflection. PRefLexOR's recursive and iterative nature directly addresses this by incorporating explicit thinking and reflection phases.
- Enhancing Situational Awareness: Unlike traditional physics or data-driven models that lack situational awareness and cannot assess their own predictions, PRefLexOR aims to include this capability through self-reflection and error correction. This is particularly valuable for challenging problems like inverse materials design.
- Enabling Deeper Domain Knowledge: The iterative, on-the-fly training method provides deep domain knowledge, especially in specialized fields like biological materials science. This contrasts with non-fine-tuned general-purpose models that provide generic responses lacking domain-specific reasoning.
- Facilitating Interdisciplinary Discovery: A remarkable finding is the model's capacity for interdisciplinary reasoning and making connections between seemingly disparate fields. This is exemplified by the analogy drawn between Hermann Hesse's philosophical novel The Glass Bead Game and the hierarchical structure of proteins. This ability to bridge abstract concepts and scientific phenomena can lead to novel insights.
- Potential for Complex Problem Solving: The framework's ability to understand and summarize complex research abstracts from data not included in training and propose future research directions demonstrates a high level of reasoning and strategic vision, indicative of potential for automating parts of the scientific discovery process.
- Efficiency and Accessibility: The success achieved with a relatively small model (3 billion parameters) is significant. This suggests that advanced reasoning capabilities can be instilled in models that are easier to implement and run on local systems compared to larger, more resource-intensive frontier models.
The recursive optimization strategy, inspired by biological systems' adaptability, allows the model to refine its reasoning through iterative feedback, enhancing decision-making, coherence, and adaptability.
This aligns with the broader goal of developing models that capture scientific processes for solving cross-disciplinary problems, making them indispensable tools in fields like biomaterials research.
Summary of Results
The research evaluated PRefLexOR through a series of inference experiments and quantitative analysis, particularly focusing on a fine-tuned model based on a small 3 billion parameter Llama-3.2-3B-Instruct model. The model was trained on 500 scientific papers in the domain of biological and bio-inspired materials.
Several inference examples showcased the model's reasoning capabilities:
- Hierarchical Structures: Asked why hierarchical structures work well without mentioning materials, the model used its "thinking" section to dissect the concept, identifying advantages like energy dissipation and size adaptation and connecting them to materials properties and applications like nacre.
- Biological Materials Failure: In response to a query about graceful failure in biological materials, the "thinking" section elaborated on mechanisms such as viscoelasticity, crack bridging, and fiber sliding, linking them to the hierarchical structure. The final answer synthesized these points into a coherent explanation, demonstrating a deep grasp of advanced materials science principles and connecting concepts to examples like bone and nacre.
- Glass Bead Game Analogy: A high-level task involving connecting Hermann Hesse's The Glass Bead Game (a philosophical concept about interconnected knowledge) and the science of proteins. The model successfully drew parallels based on shared hierarchical structures, functional characteristics (adaptability, interconnectedness), and dynamic aspects. This example highlighted the model's capacity for advanced interdisciplinary thinking, abstraction, synthesis, and analogy, skills typically seen in subject-matter experts.
- Research Abstract Analysis: The model was given an abstract from an unseen paper on myco-composites and asked to summarize and propose research directions. The "thinking" section provided a comprehensive analysis and proposed a well-framed hypothesis and eight specific research proposals, demonstrating the ability to apply its reasoning strategy to a new task and exhibit high-level domain and interdisciplinary knowledge and creative thinking.
These examples qualitatively demonstrate the model's sophisticated interdisciplinary reasoning and ability to generalize learned reasoning steps. The structured reflection in the "thinking" section was particularly noted as suggesting advanced reasoning capability.
Recursive Reasoning Algorithm
The researchers also explored implementing a Recursive Reasoning Algorithm by incorporating explicit reflection phases, triggered by special tokens like <∣thinking∣>, <∣/thinking∣>, <∣reflect∣>, and <∣/reflect∣>.
This algorithm iteratively improves responses. The process involves the Reasoning Model generating an initial response, extracting a reflection, using a critic model (or the model itself in reflection) to suggest improvements to the thinking process, and generating a new response based on the refined thinking.
This cycle continues for a set number of iterations or until quality criteria are met, and the final output can be the last iteration's response or an integration of all iterations.
Figure 6 illustrates this recursive reasoning algorithm using thinking and reflection tokens.

Fig. 6: PRefLexOR recursive reasoning algorithm: an iterative approach leveraging a fine-tuned reasoning model and a general-purpose critic model.
The effectiveness of this recursive approach was quantitatively assessed using GPT-4o as a critic to score responses over three iterations (i=0, i=1, i=2) based on coherency, accuracy, depth of explanation, and clarity.
For the question "How do biological materials fail gracefully?", the scores improved significantly from iteration i=0 to i=2, with the final iteration achieving the highest average score (8.75/10) and demonstrating increased detail, accuracy, and comprehensiveness (e.g., including quantitative information and loading conditions).
Table 1 compares features present in the responses across three iterations, showing the progressive improvement in detail and comprehensiveness.
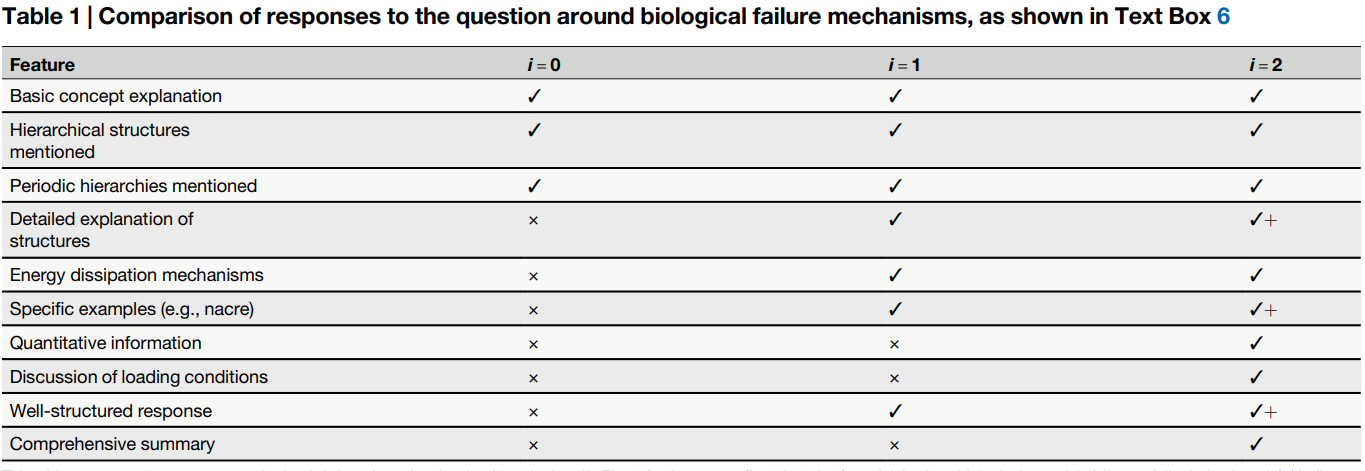
Table 1 Comparison of responses to the question around biological failure mechanisms... (Table 1 shows a table with features (Basic concept, Hierarchical structures, Energy dissipation, etc.) and columns for i=0, i=1, i=2, using checkmarks and crosses to show presence/absence of features, indicating improvement over iterations.]
Figure 7 visualizes the quantitative scores across the three iterations, clearly showing the increase in scores for accuracy, depth, clarity, and overall average.
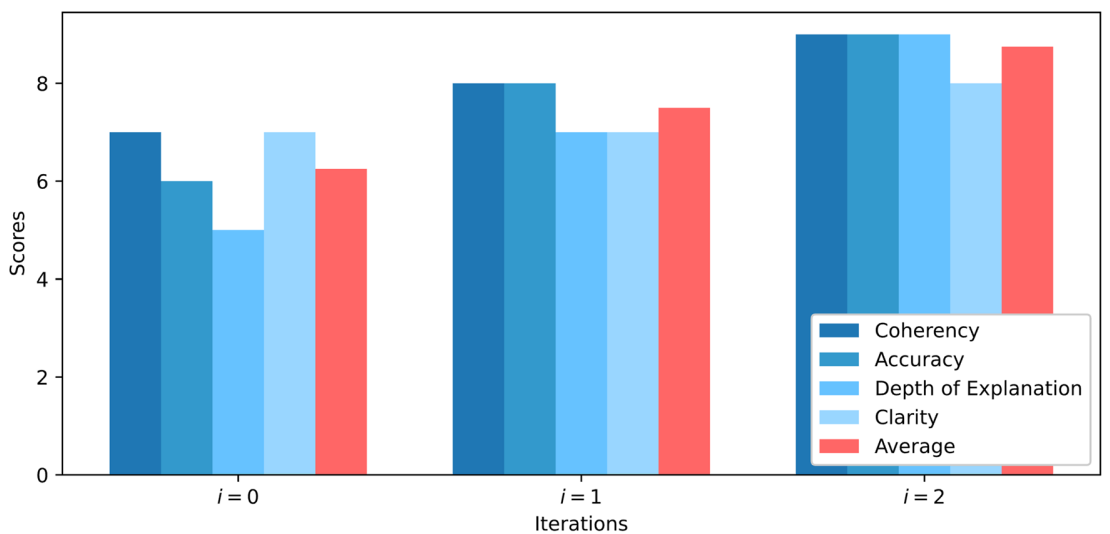
Fig. 7: Scores of model responses to the question “How do biological materials fail gracefully” across three iterations... (Figure 7 is a bar chart showing scores for Coherency, Accuracy, Depth, Clarity, and Average across three iterations (i=0, i=1, i=2), with bars rising from i=0 to i=2.]
The paper also showed that recursive sampling could be implemented even in a thinking-only model (without explicit reflection tokens) using a multi-agent strategy where a Critic agent produces reflection to improve the thinking process. Similar iterative improvements in scores
Comparing PRefLexOR's output to a non-fine-tuned base model and a general-purpose commercial model (GPT-4o), the PRefLexOR model trained on scientific data provided responses that were significantly more aligned with the biological materials science domain, offered deeper technical analysis, and crucially, included the structured "thinking" and "reflection" components that were absent in the baseline models.
Conclusion
The PRefLexOR framework successfully addresses the challenge of endowing language models with enhanced scientific reasoning capabilities, particularly within specialized domains like biological materials science.
By integrating preference optimization, reinforcement learning concepts, and a recursive approach, PRefLexOR enables models to refine their thinking iteratively and generate more sophisticated, accurate, and comprehensive responses. The use of in-situ dataset generation is a notable solution to the difficulty of acquiring preference data for complex reasoning tasks.
The results demonstrate that PRefLexOR can instill advanced reasoning skills, interdisciplinary thinking capabilities, and the ability to generalize to new tasks even in relatively small models. The recursive reasoning algorithm, whether implemented with explicit reflection tokens or a multi-agent critic, shows promising improvements in response quality over iterations.
The significant difference observed between PRefLexOR's domain-aligned, reflective responses and the generic outputs of baseline models underscores the framework's effectiveness.
The potential for future work outlined in the sources is vast. This includes exploring the integration of PRefLexOR concepts with ideas from Hermann Hesse's Glass Bead Game to simulate collaborative, interdisciplinary thinking through multi-agent systems and symbolic representation.
Future directions also include refining reasoning strategies, exploring graph-native reasoning, incorporating symbolic reflection during thinking, triggering different strategies based on task type, and leveraging symbolic reasoning for generalization.
The PRefLexOR framework represents a significant step towards developing generative AI models capable of deeper, more adaptable, and interdisciplinary scientific reasoning. By focusing on the process of thought and reflection, rather than just the final output, it offers a promising pathway towards creating AI that can function as a collaborative partner in scientific discovery and complex problem-solving.


New AI Framework PRefLexOR Teaches Itself to Reason Like a Scientist
PRefLexOR: preference-based recursive language modeling for exploratory optimization of reasoning and agentic thinking