The recent study titled "L²M: Mutual Information Scaling Law for Long-Context Language Modeling" introduces a pivotal advancement in understanding how language models can effectively manage long-range dependencies in natural language processing (NLP). By establishing a bipartite mutual information scaling law, the authors provide a theoretical framework that aligns a model's internal memory capacity with the length of the context it processes, offering significant insights for the development of more efficient and capable language models.
https://arxiv.org/abs/2503.04725
Key Takeaways:
Bipartite Mutual Information Scaling Law: The study identifies a distinct scaling behavior in natural language, where the mutual information between two segments of text follows a power-law relationship with respect to their separation distance. This differs from conventional two-point mutual information metrics and is crucial for understanding long-context dependencies.
L²M Condition: Based on the scaling law, the Long-context Language Modeling (L²M) condition is formulated. This condition specifies that a model's latent state size must scale proportionally to the bipartite mutual information to effectively capture long-range dependencies.
Empirical Validation: The theoretical findings are validated through experiments on both transformer architectures and state space models, demonstrating that models adhering to the L²M condition exhibit improved performance in long-context language modeling tasks.
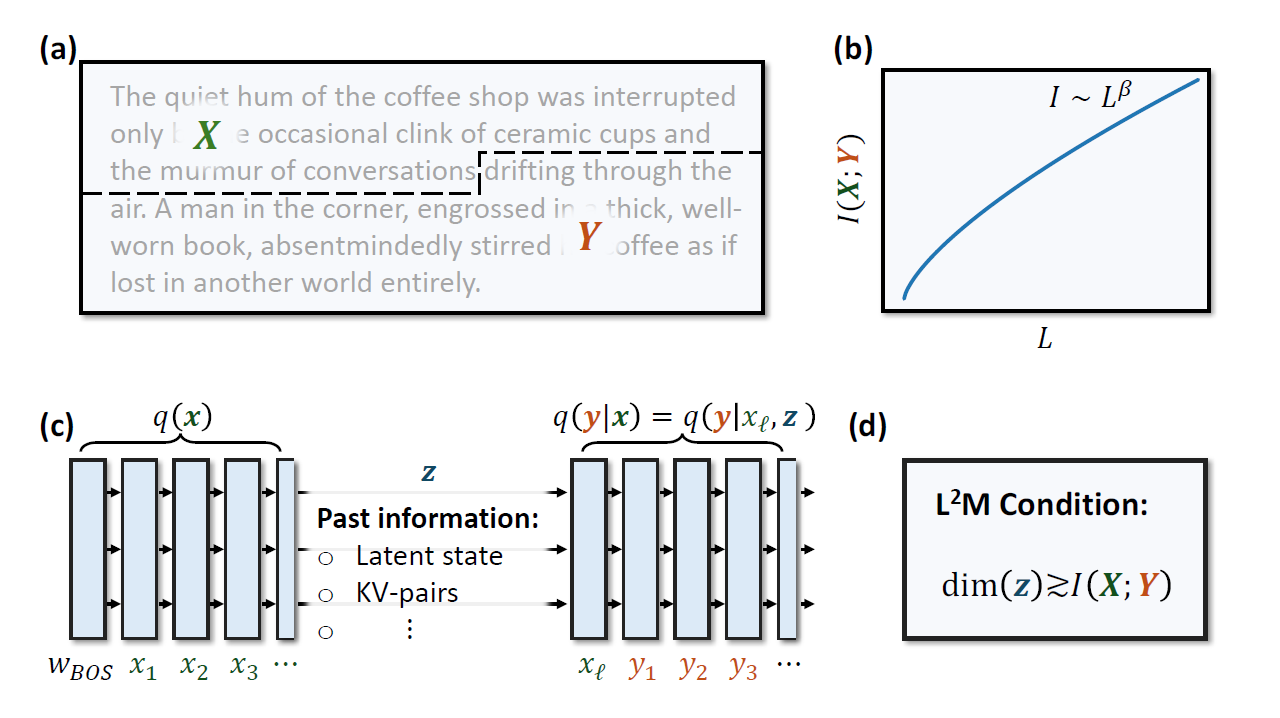
Figure 1. Illustration of the central idea of our paper. (a) A random block of text of length L is divided into two parts X and Y . (b) The (bipartite) mutual information between the random variables X and Y has a power-law scaling with respect to the length. (c) Autoregressive neural networks parameterize conditional distributions q(y|x) = (y|xℓ, z) via a hidden state z that caches past information. (d) We formulate the Long-context Language Modeling
(L2M) condition, which states that a model’s state size for storing past information must grow at least as the power-law scaling of the bipartite mutual information for effective long context length modeling.
Overview
In natural language, understanding and modeling long-range dependencies are essential for tasks such as document summarization, dialogue systems, and complex reasoning. Traditional language models often struggle with these dependencies due to limitations in their architectures and computational resources. The L²M study addresses this challenge by introducing a bipartite mutual information scaling law, which quantifies the relationship between two distant segments of text. This law reveals that the mutual information between these segments scales as a power of their separation distance, providing a more accurate representation of long-range dependencies than traditional metrics. citeturn0search0
Building upon this scaling law, the authors propose the L²M condition, which dictates that a language model's internal memory (latent state size) must scale in accordance with the bipartite mutual information to effectively model long contexts. This condition offers a theoretical foundation for designing models capable of handling extended context lengths without compromising performance.
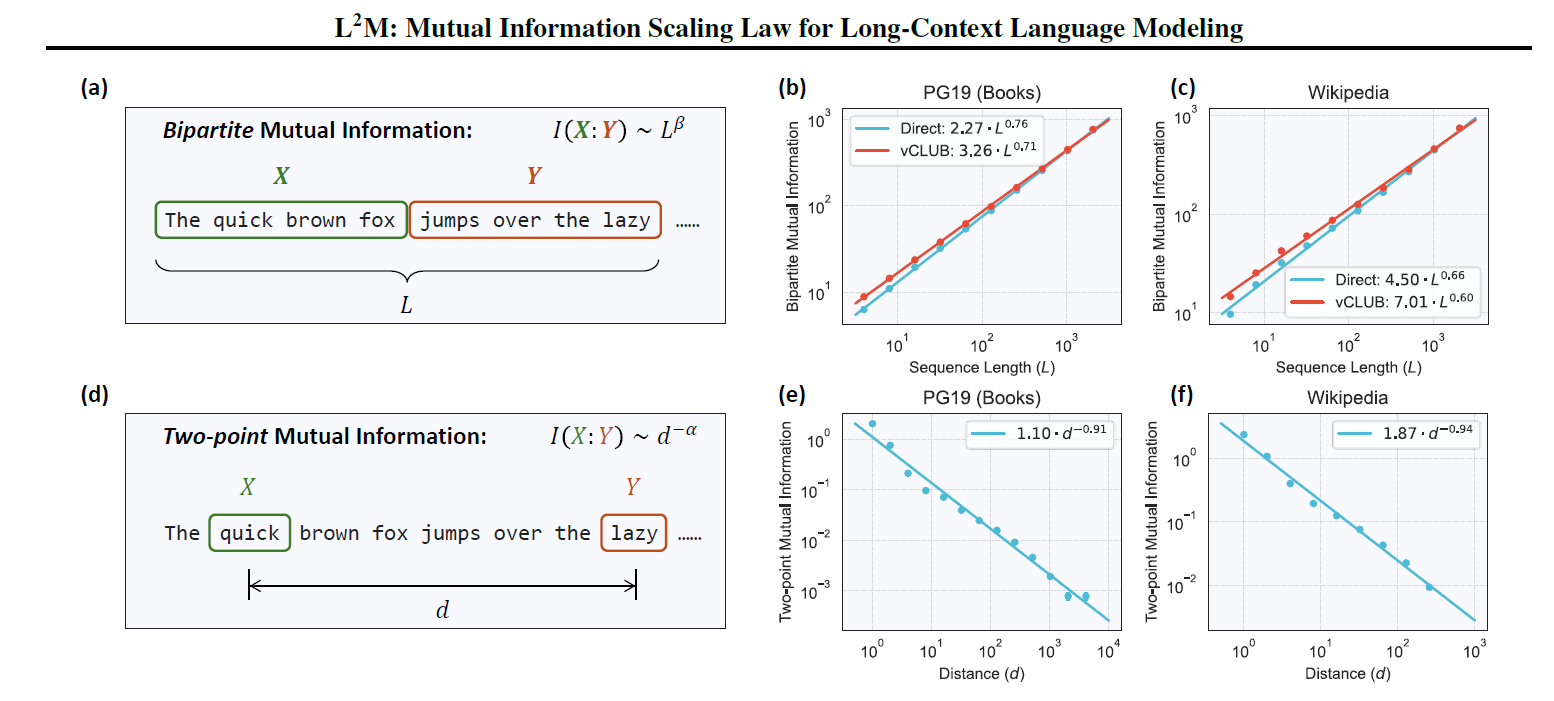
Figure 2. Illustration and estimations of bipartite and two-point mutual information in natural language. (a) The bipartite mutual information measures statistical dependence between two adjacent segments within a text block of length L. (b, c) Estimations using LLaMA 3.1 405B model (Meta) on PG19 dataset (Rae et al., 2020) of pre-1919 books and WIKIPEDIA (Foundation). Both direct estimation and vCLUB approximation (Cheng et al., 2020) show consistent results across datasets. See Appx. A.IV for results using DeepSeek and other LLaMA models. (d) The two-point mutual information measures statistical dependence between tokens separated by distance d. (e, f) Two-point mutual information estimations on PG19 dataset and WIKIPEDIA
Why It's Important
The implications of the L²M condition are profound for the future of NLP and the development of large language models (LLMs). By aligning a model's memory capacity with the intrinsic properties of natural language, developers can create models that are both more efficient and more effective in processing long texts. This alignment is particularly crucial as applications demand the handling of longer documents and more complex interactions.
Moreover, the study challenges existing assumptions about mutual information in language modeling. The identification of a distinct bipartite mutual information scaling law suggests that previous models may have underestimated the complexity of long-range dependencies. Recognizing and incorporating this scaling behavior can lead to more accurate and robust language models.
The findings have implications beyond language modeling. The principles established in the L²M framework could be applied to other domains requiring long-context understanding, such as legal document analysis, scientific research, and complex reasoning tasks. Moreover, the research suggests that designing synthetic language datasets with proper mutual information scaling could enhance the training of language models, leading to more robust and capable systems.
Ethical Considerations
While the advancements in long-context modeling are promising, they also raise ethical considerations. Improved long-context modeling could amplify existing challenges in LLMs, including the propagation of biases over longer contexts and enhanced capabilities for generating persuasive misinformation. Researchers and developers must consider these ethical dimensions and work towards ensuring that improvements in long-range dependency modeling are accompanied by advances in model safety, fairness, and the verifiability of model outputs.
Summary of Results
The authors conducted extensive experiments using transformer-based models and state space models to validate the L²M condition. These experiments demonstrated that models designed with latent state sizes scaling according to the bipartite mutual information exhibited superior performance in tasks involving long-context dependencies. Conversely, models that did not adhere to this scaling showed degraded performance, underscoring the necessity of the L²M condition for effective long-context language modeling.
Conclusion
The L²M study provides a critical theoretical advancement in understanding how to model long-range dependencies in natural language. By establishing the bipartite mutual information scaling law and the corresponding L²M condition, the authors offer a clear guideline for designing language models capable of effectively handling extended contexts. This research not only enhances the performance of current NLP applications but also paves the way for future innovations in language modeling and artificial intelligence.

Information Scaling Law for Long-Context Language Modeling