
Anyone 2 can produce high-fidelity results that seamlessly integrate characters with the surrounding environment.
Just released research from Alibaba group reviews progress in Animate Anyone 2. AA2 makes significant advances in the area of environment integration achieving high-fidelity results that maintain character consistency and blend with surroundings. The work is progress made on the original Animate Anyone by the group and it compares with the likes of UniAnimate, Champ and MagicAnimate.
The objective of character image animation is to synthesize animated video sequences utilizing a reference character image and a sequence of motion signals
The diffusion based animation process generates more consistent character and environment interactions producing stunning video clips that are difficult to visually recognize as modified. The new process utilizes motion signals and environmental context representations from a driving video to create a realistic background and subject interaction. The unique masking process more accurately maintains the reference character creating realistic placement of the character in scene.
A review of the videos examples presented shows clearly that there is marked improvement over previous Animate Anyone as well as competitors. However there is still much room for improvement in areas such as intricate movements, interactions, and shadows. I also noticed that many of the examples showed some mask drift which can create distortions in the character edge and environment during playback.

Referencing character shows distortion in facial features

Distortions in intricate interactions are prevalent but less noticeable than previous versions.

Style transfer is improved but inconsistent leading to fluctuations on subject during movement and inaccurate transfer in some situations.
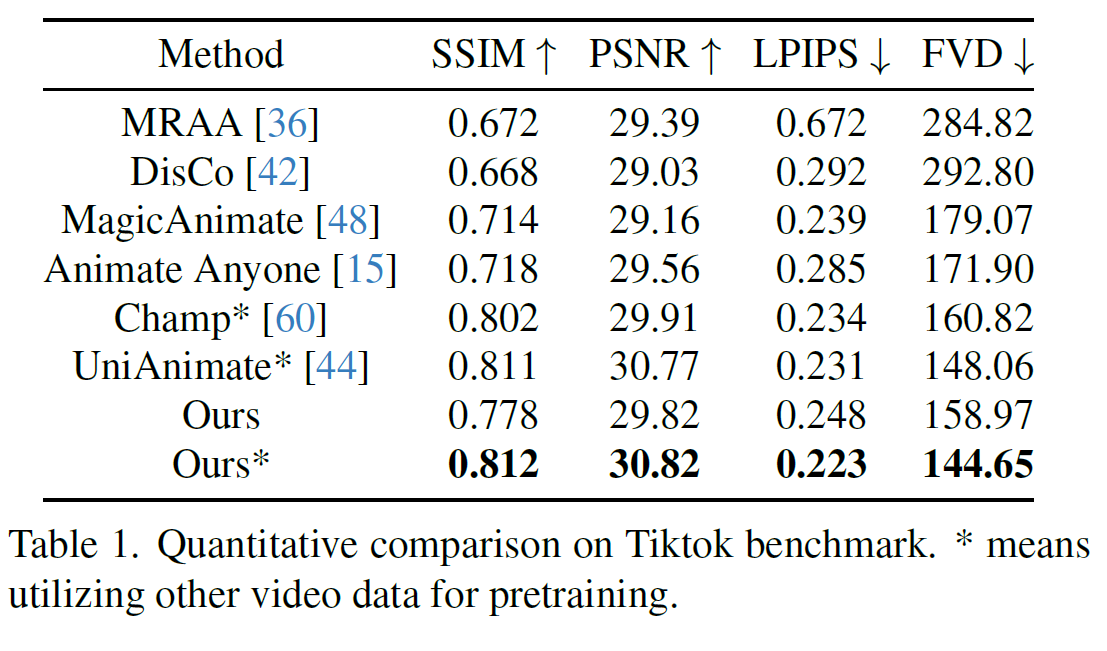
A quantitative comparison against similar animation techniques illustrates Animate Anyone 2's improved performance over other industry leading processes. To ensure a fair comparison, they adjusted the configuration of the method: instead of using the ground truth background, the background from the reference image is used as the environmental input. This modification allows all methods to generate outputs conditioned exclusively on a single reference image. The results are shown in the tables below.
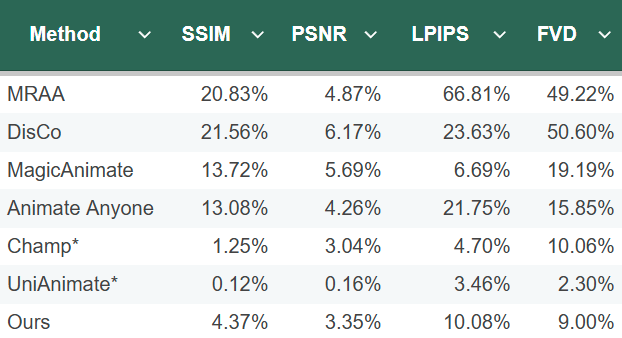
Quantitative improvement on Tiktok benchmark. * means utilizing other video data for pretraining.
MRAA: Motion Representation for Articulated Animation
DisCo: Disentangled Control for Realistic Human Dance Generation
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
SSIM (Structural Similarity Index Measure):
- SSIM is a perceptual metric that quantifies image quality degradation caused by processing such as data compression or transmission losses.
- It measures the similarity between two images, considering changes in structural information, luminance, and contrast.
- The SSIM value ranges from -1 to 1, where 1 indicates perfect similarity.
PSNR (Peak Signal-to-Noise Ratio):
- PSNR is a common metric used to measure the quality of reconstruction of lossy compression codecs.
- It is the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation.
- PSNR is usually expressed in logarithmic decibel scale. Higher PSNR generally indicates better quality.
LPIPS (Learned Perceptual Image Patch Similarity):
- LPIPS is a perceptual metric that measures the similarity between two images based on deep network features.
- It uses a pre-trained deep neural network to compare image patches, capturing perceptual differences that are more aligned with human judgment.
- Lower LPIPS values indicate higher perceptual similarity between images.
FVD (Frechet Video Distance):
- FVD is a metric used to evaluate the quality of generated videos.
- It measures the distance between the feature distributions of real and generated videos, using a pre-trained video feature extractor.
- Lower FVD values indicate that the generated videos are more similar to the real videos in terms of their feature distributions.
The process, the method of image generation for the character and background involves several steps:
Training Phase:
- The authors employ a self-supervised learning strategy.
- They use a reference video and disentangle the character and environment via a formulated mask, obtaining separate character sequences and environment sequences.
- They also extract the sequence of objects to facilitate more fidelity in object interaction.
- The character image is randomly sampled from the character sequence with a center crop and composited onto a random background.
- The model reconstructs the reference video using the character image, motion sequence, environment sequence, and object sequence as inputs.
Inference Phase:
- Given a target character image and a driving video, the method animates the character with consistent actions and environmental relationships corresponding to the driving video.
- The environment is formulated as regions devoid of characters and incorporated as model input, enabling end-to-end learning of character-environment fusion.
- Features of objects interacting with the character are injected into the denoising process via spatial blending to preserve object interactions.
- A pose modulation approach is used to better represent the spatial relationships between body limbs, handling more diverse motions.
This approach ensures that the generated character animations maintain coherence with the environmental context and exhibits high-fidelity interactions with the surrounding environment.
While the results are surely an improvement over the previous version as well as many of the competitors, there is still significant progress to be made before it is a viable process for high end content generation, eg. movies and advertising. Improvements to the architecture and computing efficiency will lead to composites that can be used commercially and personally for a wide range of applications.
The ramifications of such technology cannot go unnoticed. While it offers promising applications in fields like entertainment, education, and virtual reality, enabling creators to produce immersive and dynamic content with ease, it also raises concerns about potential misuse. The ability to generate highly realistic animations could lead to the creation of deceptive media, such as deepfakes, which may be used to spread misinformation or manipulate public opinion. As Animate Anyone 2 and similar technologies continue to evolve, it is imperative for developers, policymakers, and society at large to engage in discussions about ethical guidelines and implement safeguards to prevent malicious applications, ensuring that the technology serves as a force for good.


Alibaba Research Releases Animate Anyone 2: An Improved Character Animator with Environment Integration Using Diffusion