The world of information retrieval has long grappled with the complexity and computational demands of multi-vector models. MUVERA, a groundbreaking algorithm, is changing the game by converting these demanding processes into a highly efficient single-vector approach. This innovation paves the way for faster, more scalable, and manageable retrieval systems—reshaping what's possible in advanced search and AI-powered applications.
Key Innovations at the Core of MUVERA
- Fixed Dimensional Encodings (FDEs): MUVERA encapsulates entire sets of vector embeddings into a single vector. This enables the use of high-speed Maximum Inner Product Search (MIPS) solvers, streamlining what was once a cumbersome process.
- Theoretical Guarantees: FDEs are designed with provable ε-approximation guarantees to the multi-vector Chamfer similarity, ensuring both reliability and performance.
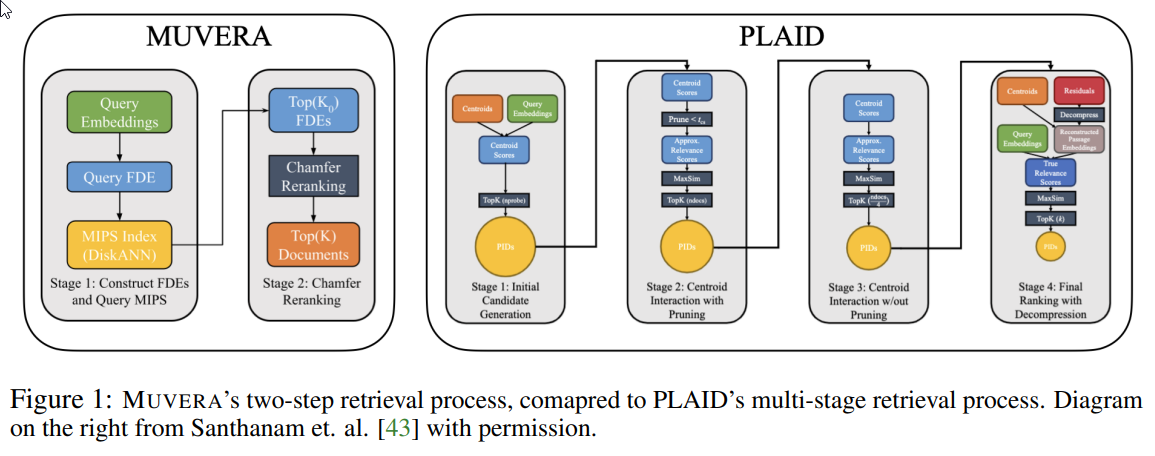
- Superior Efficiency: In real-world testing, MUVERA outperformed established systems like PLAID, achieving 10% higher recall rates while reducing latency by a dramatic 90% across numerous datasets.
- Resource Optimization: It retrieves significantly fewer candidates than traditional heuristics for the same recall rate, and its product quantization compresses FDEs by up to 32x without significant loss in quality.
- Practical Robustness: MUVERA maintains high recall and low latency with minimal parameter tuning, making it ideal for large-scale, real-world deployments.
- Wide-Reaching Applications: These advances are especially impactful for large language models (LLMs) and other AI systems that depend on efficient, scalable retrieval methods.
How MUVERA’s Approach Works
Traditional single-vector retrieval models trade off expressiveness for speed, while multi-vector systems like ColBERT offer nuanced representations at great computational cost. The Chamfer similarity metric, key to multi-vector methods, is incompatible with the fastest search infrastructures, forcing prior solutions into inefficient workflows.
MUVERA disrupts this paradigm by introducing FDEs, compact single vectors that faithfully approximate the behavior of entire sets of embeddings. Using locality-sensitive hashing (LSH) such as SimHash, MUVERA partitions and summarizes embeddings, then combines results through concatenation. Multiple random partitions and projections ensure robustness and compression, culminating in a single vector that stands in for the complex multi-vector comparison process.
After forming FDEs, the system applies optimized MIPS solvers (like DiskANN) for ultra-fast retrieval, followed by a simplified re-ranking phase using the original Chamfer metric. Techniques like "ball carving" further accelerate query processing by pre-clustering similar queries.
The Significance of MUVERA
By bridging the divide between multi-vector expressiveness and single-vector speed, MUVERA allows advanced neural retrieval systems to fully leverage established MIPS infrastructure. Its theoretical foundations provide confidence in performance, and the efficient product quantization makes it feasible to handle massive datasets. This is critical for high-stakes applications, where both speed and reliability matter.
For LLMs and retrieval-augmented AI systems, MUVERA’s improvements mean faster, more economical, and more responsive models. Its principles also have potential in fields like computer vision, where Chamfer similarity plays a pivotal role, hinting at even broader impacts.
Real-World Validation
- Recall and Performance: FDEs consistently improved recall as dimensionality increased, offering predictable and tunable results.
- Clustering Flexibility: SimHash provided similar results to k-means while being more adaptable across datasets.
- Efficiency Gains: For fixed recall, MUVERA retrieved far fewer candidates than single-vector heuristics up to five times fewer in some scenarios.
- Stability and Consistency: The randomized steps in FDE creation had negligible impact, with consistently strong performance.
- Compression and Throughput: Product quantization reduced FDE storage requirements by 32x and improved query throughput by up to 20x, with little effect on recall.
- End-to-End Results: Across BEIR benchmarks, MUVERA matched or exceeded the performance of PLAID but with far greater efficiency and almost no tuning required.
A New Standard for Retrieval
MUVERA is a principled, practical solution to the challenges of multi-vector retrieval. By merging the strengths of expressive models and efficient search, it delivers unmatched accuracy, speed, and scalability. Its robust theoretical underpinnings, proven real-world results, and powerful memory optimizations signal a major leap forward for AI-driven information retrieval benefiting everything from search engines to next-generation language models.


MUVERA Multi-Vector Information Retrieval
MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings