Open-source AI is entering a new phase, with MiroMind-M1 leading the charge in mathematical reasoning. This project goes beyond simply releasing models by offering full transparency, every model, dataset, and configuration is openly available. This approach not only accelerates research but also ensures reproducibility, a critical factor for scientific progress in artificial intelligence.
Key Innovations and Methodologies
- Comprehensive Open Source Stack: MiroMind-M1 provides models at both 7B and 32B parameter scales, along with over 700,000 curated data examples and complete training configurations. This level of openness allows researchers to benchmark, iterate, and improve upon the work without hidden barriers.
- Two-Stage Training Paradigm:
- Supervised Fine-Tuning (SFT): The models are initially trained on a vast collection of math problems with detailed Chain-of-Thought (CoT) reasoning, teaching them to handle complex, multi-step logic.
- Reinforcement Learning with Verifiable Reward (RLVR): Training continues with reinforcement learning, where an external verifier confirms solution accuracy, ensuring only correct outputs are rewarded.
- Context-Aware Multi-Stage Policy Optimization (CAMPO): This new algorithm addresses common reinforcement learning pitfalls by using length-progressive training and adaptive repetition penalties. CAMPO helps the model produce longer, context-sensitive reasoning traces while avoiding repetitive or unstable outputs.
- Superior Token Efficiency: MiroMind-M1 models generate accurate answers using fewer tokens, making them faster and more cost-effective, an essential trait for practical deployment.
- Rigorous Data Curation and Verification: All data is carefully deduplicated and decontaminated, ensuring fair evaluation and reliable benchmarking. An upgraded math verifier is released, providing robust reward signals during RL training.
Why MiroMind-M1 Matters
By open-sourcing the entire pipeline, MiroMind-M1 raises the bar for transparency in AI research. Mathematical reasoning tasks are particularly challenging, requiring precise, stepwise logic that translates well to broader domains like planning and code generation. Advancements here signal the potential for AI systems to handle more complex, interpretable reasoning across disciplines.
The introduction of CAMPO is especially noteworthy. By penalizing repetition and gradually increasing task difficulty, models learn robust strategies efficiently, maintaining accuracy and stability. The result is a system that delivers succinct, reliable solutions, an important step toward practical, trustworthy AI.
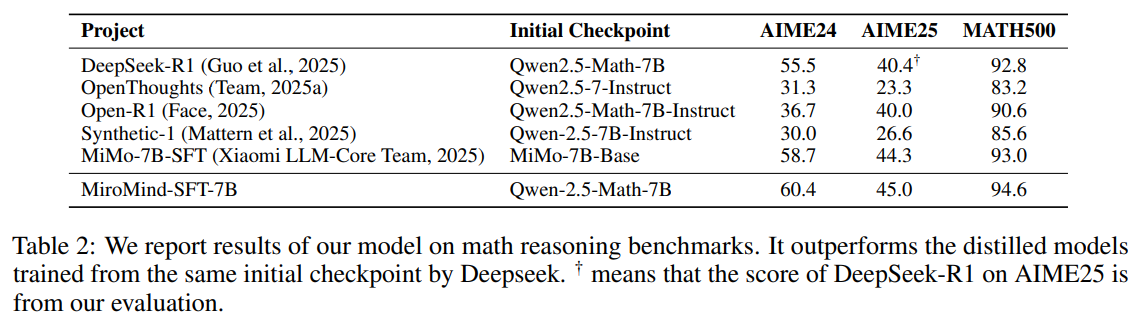
Performance Highlights and Insights
- Outperforming Peers:
- MiroMind-M1 surpasses other open-source models of similar size on standard math reasoning benchmarks, thanks to its rich data and advanced training approach.
- MiroMind-M1 surpasses other open-source models of similar size on standard math reasoning benchmarks, thanks to its rich data and advanced training approach.
- Importance of Data and Training Strategies:
- Longer, detailed reasoning chains in the training data significantly boost model performance, showing the value of depth in Chain-of-Thought traces.
- Training sequences individually (“no-packing”) increases accuracy, while hybrid approaches can balance speed and effectiveness.

- CAMPO’s Impact:
- CAMPO increases both answer accuracy and token efficiency, allowing the model to solve problems in fewer words without sacrificing quality.
- The repetition penalty and improved verifier create stable, effective reinforcement learning, preventing exploitation of weak reward signals.
- Multi-stage training, where output length is gradually increased, accelerates learning and enhances final accuracy, especially under limited token budgets.
- Evaluation Nuances:
- On small, challenging benchmarks, results can vary between runs, emphasizing the need for careful interpretation of evaluation metrics.
A Blueprint for Future AI Research
MiroMind-M1 reimagines open-source mathematical reasoning in large language models. By sharing every component, from models and datasets to training strategies, it sets a high standard for community-driven innovation and rigorous research. Innovations like CAMPO not only enhance transparency but also create more stable, efficient, and interpretable AI systems. MiroMind-M1 is both a valuable tool for current research and a foundation for building even more capable reasoning models in the future.


MiroMind-M1: Redefining Open-Source Mathematical Reasoning for AI
MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization