
 GRAPHIC APPAREL SHOP
GRAPHIC APPAREL SHOPDo larger language models naturally learn to reason, or do they mostly get better at recalling facts and mimicking patterns? A new study introduces a Clinical Trial Natural Language Inference benchmark that directly tests this question and finds a striking dissociation: models often possess the right clinical knowledge but fail to deploy it reliably for inference.
The authors formalize four reasoning families that underlie clinical judgment, including causal attribution, compositional grounding, epistemic verification, and risk state abstraction, and pair every example with a targeted Ground Knowledge and Meta Level Reasoning Verification (GKMRV) probe.
These GKMRV probes measure whether a model holds the relevant facts and whether it can recognize correct or incorrect applications of those facts, separate from the main entailment decision.
The result is a clean way to isolate reasoning failures from knowledge gaps, an issue often blurred in scaling narratives and benchmark leaderboards (Kaplan et al., 2020); (Hoffmann et al., 2022).
Key takeaways
- Across four clinical inference tasks, models achieve near ceiling accuracy on GKMRV but low accuracy on the main NLI tasks, on average about 0.25.
- Errors are highly consistent across samples, indicating systematic heuristic shortcuts rather than random noise.
- Compositional grounding nearly collapses (about 0.04 accuracy on average) despite strong GKMRV, suggesting failures to integrate joint constraints.
- Chain of thought provides small and heterogeneous gains, often increasing verbosity without fixing the reasoning defect.
- The framework clarifies that models frequently know the clinical rule but do not know when or how to use it, highlighting architectural limits.
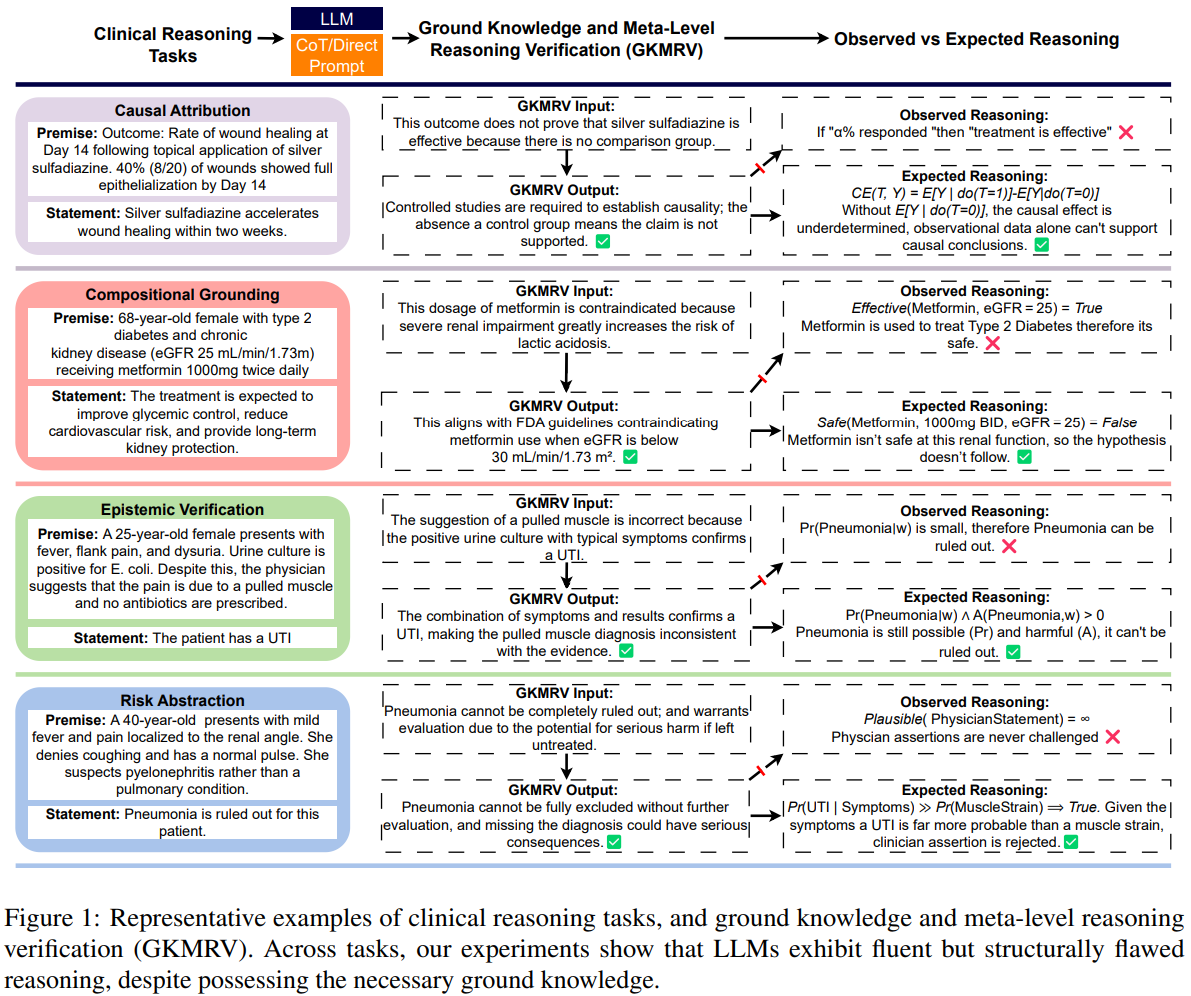
How the benchmark works
The benchmark, Clinical Trial Natural Language Inference (CTNLI), formalizes four reasoning families with parametric templates and formal semantics. For each main item the authors also construct two GKMRV probes: one that reflects correct application of the necessary knowledge and one that is a control with misapplied or incorrect knowledge. This design decouples possession of facts from inferential deployment.
The tasks are:
Causal attribution asks whether observed outcomes in a study justify a causal claim. Single arm outcomes, for example, should not license causal conclusions without counterfactual comparison. The GKMRV probe checks if the model knows that a missing comparator invalidates causal claims, a standard do-calculus intuition.
Compositional grounding requires reasoning over joint configurations (drug, dose, schedule, diagnosis, patient factors). Validity hinges on whether the full tuple is medically licensed under domain constraints. The GKMRV asks whether a configuration violates safety or protocol rules, independent of any predicted benefit.
Epistemic verification explicitly treats premises as reported assertions with sources (clinician, patient, record) rather than omniscient truth. The model must weigh evidential plausibility and resolve conflicting commitments, relating to classical frameworks for reasoning about knowledge and agent beliefs.
Risk state abstraction integrates probability and harm. A rarer but severe event can pose higher patient risk than a common minor event. The GKMRV probes whether models can articulate why high severity can dominate risk assessments even at lower frequency.
Six contemporary systems are evaluated with direct prompting and chain of thought: OpenAI o3, GPT-4o and GPT-4o mini, Gemini 2.5 Pro, DeepSeek R1, and LLaMA 3.2 3B.
Why this matters in practice
Clinical settings demand structured, context sensitive inference. A model that retrieves facts but applies shallow heuristics risks unsafe recommendations. The study provides direct evidence that performance gains from scale do not guarantee the emergence of composable internal representations for causal, compositional, epistemic, or risk reasoning, contrasting common scaling narratives.
The GKMRV design is especially important. By separating knowledge from inference, it shows that models often know the rule (for example, a comparator is required for causal claims) yet fail to apply it when labeling entailment. That pattern matches growing evidence that chain of thought rationales can be plausible but unfaithful to the true decision process (Turpin et al., 2023).
What the results show
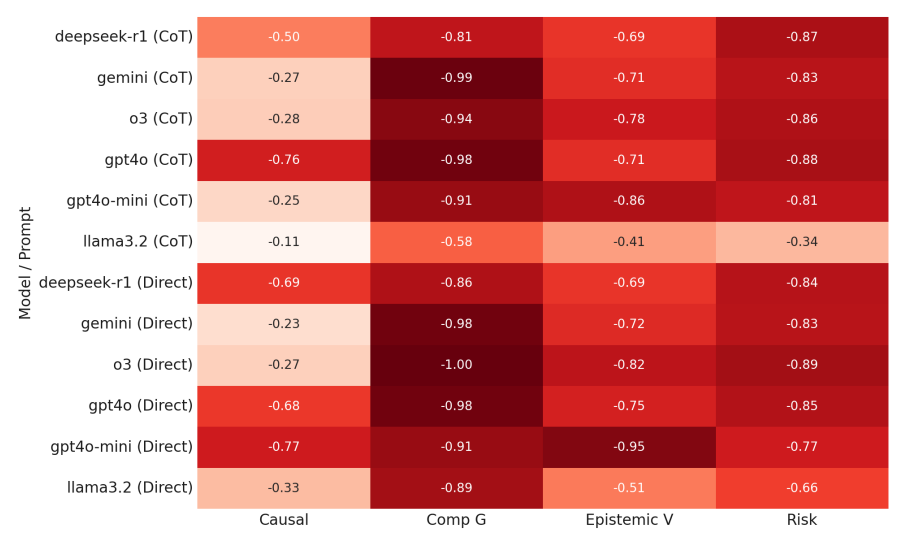
Figure 2 visualizes the gap between main task accuracy and GKMRV across the four reasoning families. Values near zero would indicate alignment between what the model knows and how it reasons. Instead, the gaps are large and consistent, with GKMRV near ceiling and main task accuracy low.
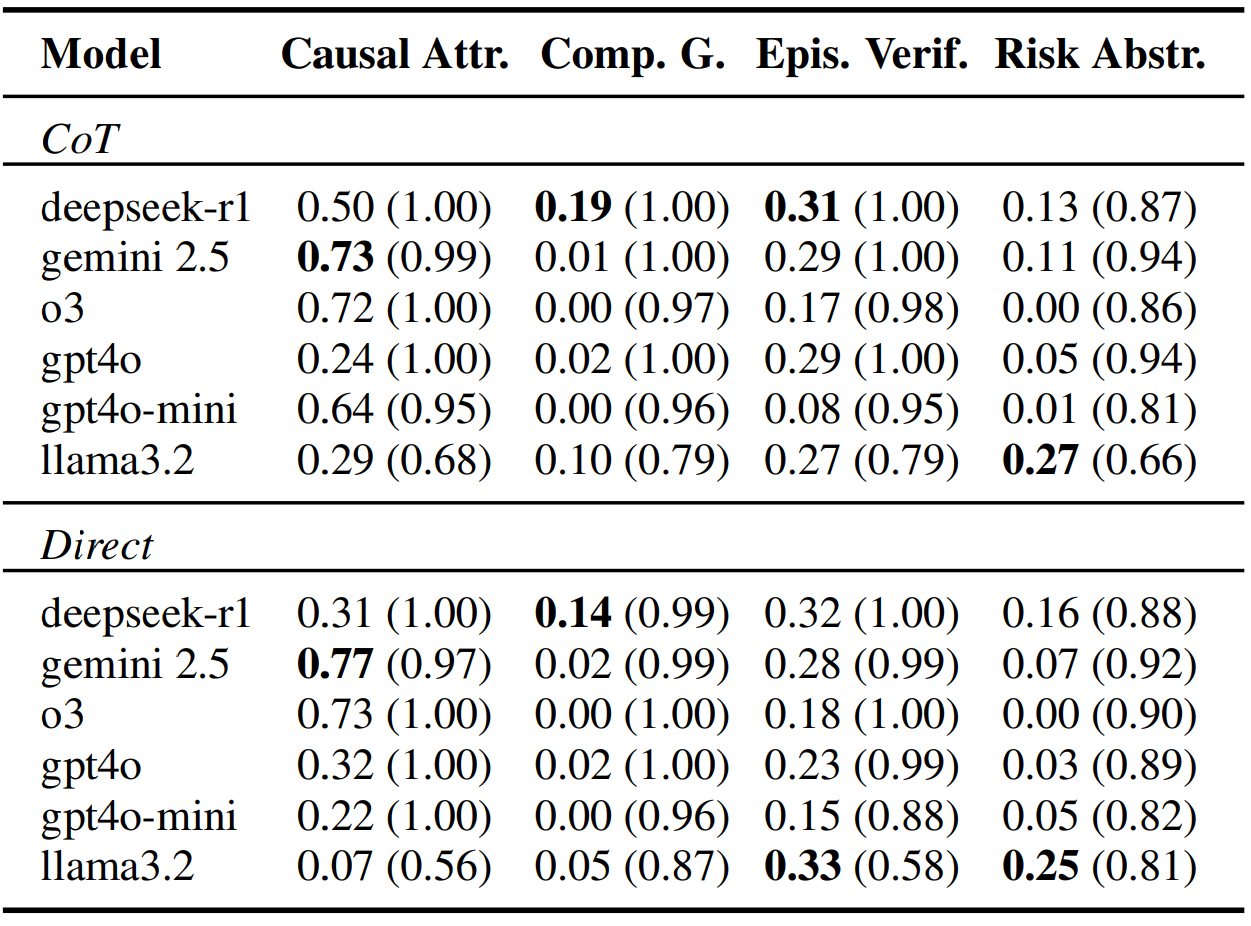
Table 5 reports per task accuracies with GKMRV in parentheses. Compositional grounding is the sharpest failure (often 0.00 to 0.02 for several models) despite excellent GKMRV (generally at or above 0.96). Causal attribution fares better, with a few models near 0.7, but still shows the same dissociation. Risk abstraction stays below roughly 0.27 across systems. Epistemic verification averages near 0.24 despite 0.95 plus GKMRV for most models.

Table 6 highlights consistency, computed as the majority label ratio across repeated completions. Values around 0.84 to 0.90 indicate that mistakes are systematic and reproducible, not sampling noise. This is strong evidence for shortcut heuristics.
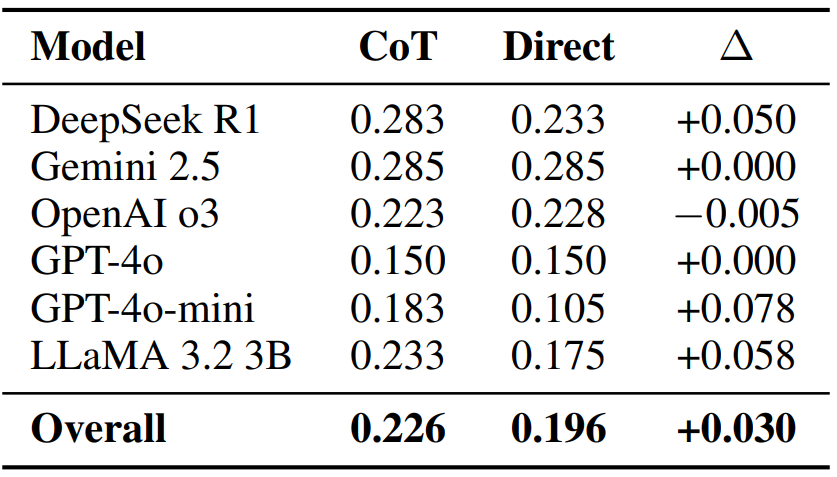
Table 7 compares direct prompting to chain of thought. Mean gains are small and uneven across models. Qualitative analysis shows that many rationales restate salient lexical cues (for example, a percentage in a single arm outcome) rather than invoking the required criterion (for example, counterfactual comparison).
Where models stumble (with concrete cases)
Causal attribution often collapses to a frequency heuristic. In a single arm wound healing example, some completions treat a 40 percent responder rate as proof of efficacy, ignoring the missing counterfactual. Yet the same models mark the GKMRV statement (no comparator, therefore no causal claim) as true. Models know the rule but fail to use it during entailment.
Compositional grounding shows failures to represent joint constraints. A high dose metformin regimen in severe renal impairment should trigger a contradiction for the claim of benefit. Instead models sometimes default to pairwise associations (metformin improves glycemic control; dose looks common) and ignore the unsafe configuration. The GKMRV correctly flags the contraindication.
Epistemic verification reveals deference to authority over evidence. With a positive urine culture and classic symptoms, the correct label is entailment for UTI, yet alternate completions treat a clinician (unsupported) alternative as decisive. GKMRV, however, correctly rejects that interpretation as implausible.
Risk state abstraction conflates unlikely with ruled out and frequency with risk. For suspected pneumonia, models sometimes endorse ruling it out because it seems unlikely, ignoring nonzero probability and high harm if missed. When comparing adverse events, models pick the most frequent minor event as highest risk, ignoring severity weighting. Again, GKMRV answers show the principles are known but not integrated during inference.
Interpretation and implications
The consistent pattern across tasks and models points to a structural limitation. Current LLMs do not appear to maintain stable, composable internal representations needed to integrate constraints, simulate counterfactuals, resolve source conflicts, or combine probability with harm. They rely on salience driven heuristics that are adequate for surface plausibility but not for principled generalization in clinical contexts (Turpin et al., 2023).
Architecturally, this motivates clearer separation of knowledge retrieval and reasoning engines, and renewed interest in neuro symbolic and probabilistic modules that explicitly model interventions, constraints, and utilities.
The authors sketch directions that include differentiable logic layers, disentangled representations, counterfactual simulation, and task specific diagnostics for compositional reasoning.
These directions align with broader efforts that combine neural models with structured reasoning and probabilistic programming, and with recent reports on frontier models where raw capability does not imply faithful reasoning (Hurst et al., 2024); (Comanici et al., 2025).
Limitations to keep in mind
The benchmark uses template instantiations with ten items per reasoning family, which trades breadth for control. Labels are strict (entailment, neutral, contradiction) while clinical reasoning can involve graded judgments.
Only two prompt types are tested and model coverage, while diverse, is not exhaustive. These design choices are transparent and make the central dissociation easier to attribute to reasoning rather than dataset artifacts, but they also bound generality.
Conclusion
This study provides a precise lens on a popular assumption about scale and reasoning. By decoupling ground knowledge from inference in a clinical NLI setting, it shows that current models can retrieve rules yet fail to apply them consistently in context. The evidence cuts across causal, compositional, epistemic, and risk reasoning.
For practitioners, the immediate guidance is caution: treat fluent answers as hypotheses that require verification, especially where safety is involved.
For researchers, the benchmark offers a reproducible test bed to stress reasoning and to evaluate architectures that integrate symbolic constraints, counterfactuals, and risk calculus. Read the paper and consider adopting the GKMRV pattern in your own evaluations to separate knowing from thinking.

Knowledge vs Reasoning in Clinical NLI
The Knowledge-Reasoning Dissociation: Fundamental Limitations of LLMs in Clinical Natural Language Inference