Gemma 3n is delivering high-performance, multimodal intelligence for developers seeking efficiency and flexibility on mobile platforms. Backed by a rapidly growing community, Gemma 3n offers a leap forward in accessible, on-device artificial intelligence.
Key Innovations in Gemma 3n
- Multimodal Mastery: Gemma 3n handles image, audio, video, and text inputs out of the box, supporting diverse use cases from voice assistants to real-time video analysis.
- Memory-Efficient Models: With 5B and 8B parameter options (optimized for effective E2B and E4B), Gemma 3n runs powerful models using as little as 2GB or 3GB of memory, making advanced AI practical on devices with limited resources.
- Cutting-Edge Architecture: Features like the MatFormer (Matryoshka Transformer), Per-Layer Embeddings (PLE), LAuReL, and AltUp optimize computation, while new audio and vision encoders are tailor-made for mobile efficiency.
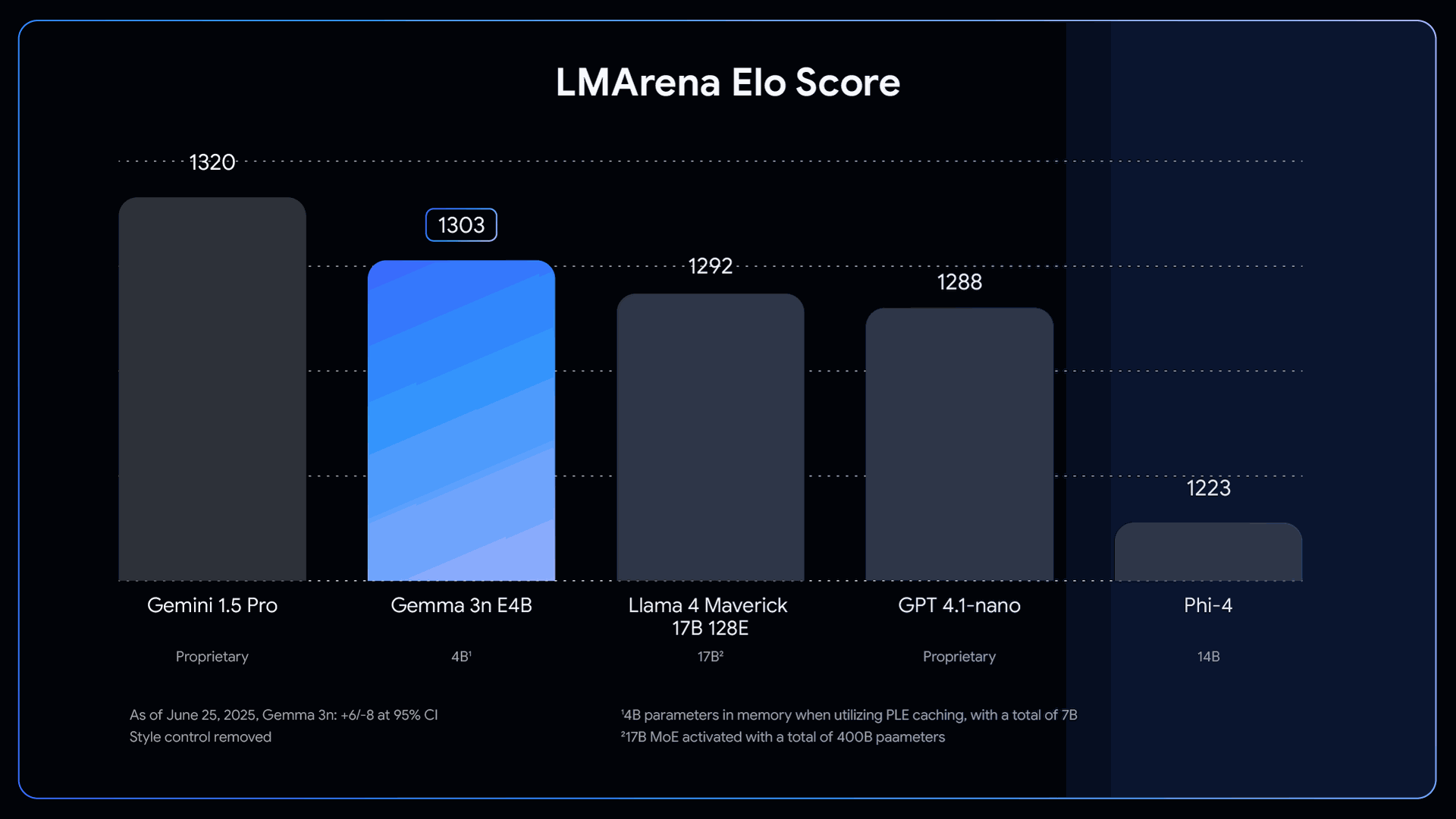
- Impressive Quality and Language Support: Covering 140 languages for text and 35 for multimodal tasks, Gemma 3n achieves industry-leading scores on math, coding, and reasoning benchmarks for compact models.
MatFormer: Flexible Architecture for Any Device
The MatFormer structure enables developers to adapt Gemma 3n for a wide range of hardware. Like a set of nested dolls, the E4B model contains a fully trained E2B sub-model, both optimized together. This approach offers:
- Instant Model Selection: Deploy the full E4B model for peak performance or the lighter E2B for faster, resource-friendly tasks.
- Custom Model Sizes: Use the MatFormer Lab tool to build custom models that fit specific device constraints, balancing memory and speed as needed.
Looking ahead, "elastic execution" will allow dynamic switching between model sizes (ie 5B to E2B auto selection) on the fly, further tuning performance and efficiency in real time.
Per-Layer Embeddings: Smarter Memory Usage
Per-Layer Embeddings (PLE) lets developers maximize model quality without taxing device memory. By shifting some computation to the CPU, Gemma 3n keeps only essential parameters in high-speed memory, making large models feasible even on modest hardware.
KV Cache Sharing: Enabling Real-Time Multimodal Experiences
Handling long audio or video streams is now quicker and smoother. With KV Cache Sharing, Gemma 3n shares key data between layers, doubling the speed of initial processing and enabling seamless, real-time interaction across modalities.
Enhanced Audio and Vision Intelligence
- Universal Speech Model Encoder: Enables on-device automatic speech recognition and translation, excelling in English and major European languages.
- MobileNet-V5 Vision Encoder: Sets new speed and accuracy standards for on-device visual intelligence, supporting multiple resolutions and real-time video up to 60 FPS—ideal for applications like augmented reality and smart cameras.
Developer Ecosystem and Community Initiatives
Gemma 3n is accessible across major platforms like Hugging Face Transformers, llama.cpp, NVIDIA, Ollama, and Docker.
Google’s Gemma 3n Impact Challenge incentivizes developers to push boundaries, offering $150,000 in prizes for the most innovative uses of the model.
Getting Started with Gemma 3n
- Experiment Instantly: Use Google AI Studio or deploy directly to Cloud Run for hands-on exploration.
- Access Model Weights: Download from Hugging Face or Kaggle for local development.
- Comprehensive Documentation: Step-by-step guides help you fine-tune and deploy Gemma 3n for various on-device scenarios.
- Seamless Integration: Compatible with Google GenAI API, Vertex AI, and open-source tools, Gemma 3n fits easily into your workflow.
Gemma 3n unlocks new possibilities for on-device AI by combining multimodal power, resource efficiency, and developer customization. Its flexible architecture and robust ecosystem empower creators to deliver smarter, faster, and more accessible AI experiences—directly on the devices people use every day.
Source: Google Developers Blog


Gemma 3n: Powering the Next Generation of On-Device AI