Imagine a coding agent that not only keeps pace with its open-source contemporaries but actually outshines them, all powered by reinforcement learning (RL). DeepSWE-Preview, a collaboration between the Agentica team and Together AI, delivers on this vision. Achieving a remarkable 59% Pass@1 on the rigorous SWE-Bench-Verified benchmark, this state-of-the-art large language model (LLM) for software engineering paves the way for open-weight agents that rival proprietary solutions.
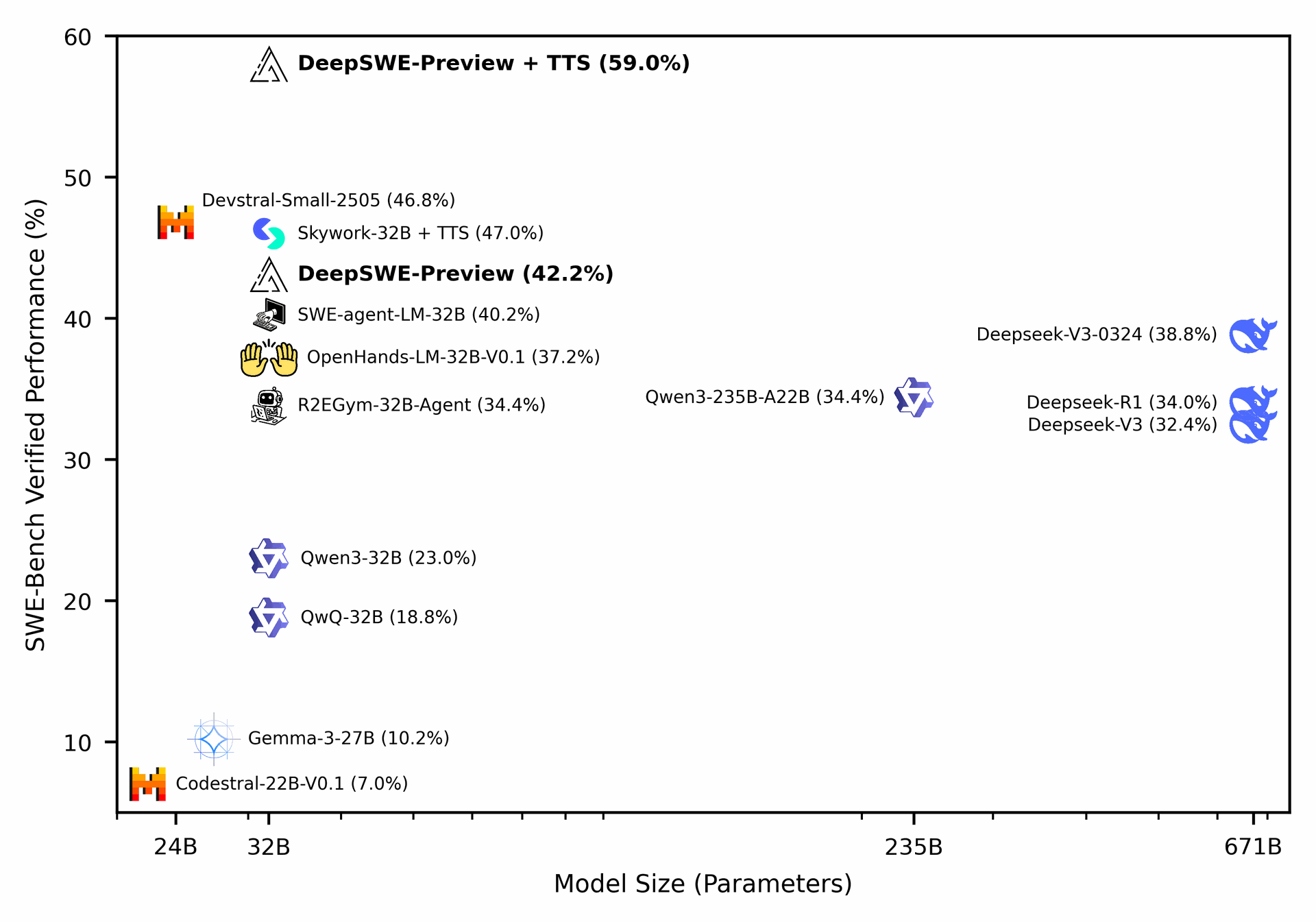 Image: Together.ai
Figure 11: Full evaluation of DeepSWE-Preview and other open-source models. DeepSWE-Preview’s Pass@1 and 16 are 42.2% and 71% respectively. With hybrid test-time scaling (TTS), DeepSWE-Preview reaches 59%.
Image: Together.ai
Figure 11: Full evaluation of DeepSWE-Preview and other open-source models. DeepSWE-Preview’s Pass@1 and 16 are 42.2% and 71% respectively. With hybrid test-time scaling (TTS), DeepSWE-Preview reaches 59%.
Innovative Training: RL-First, Open for All
DeepSWE-Preview is built on the Qwen3-32B model and trained entirely through RL, no traditional supervised fine-tuning or distillation from closed models. Leveraging Agentica’s open-source rLLM framework, the model’s full training pipeline (including datasets, code, and evaluation logs) is freely available, making results reproducible and extensible for the community.
- Robust Dataset: 4,500 real-world engineering tasks from R2E-Gym, carefully curated to avoid data leakage.
- Simulated Environments: Agents work within realistic dev environments, complete with standard IDE tools, mimicking how human engineers operate.
- Scalable Infrastructure: Integration with Kubernetes enables scaling RL training to thousands of CPU cores in parallel, optimizing both speed and resource efficiency.
RL Algorithm Enhancements: GRPO++
DeepSWE-Preview refines the Generalized Reward Policy Optimization (GRPO) approach into GRPO++, offering:
- Clip High & No KL Loss: Ensures stable learning, encouraging exploration without restricting the agent’s evolving policy.
- Length Normalization: Removes bias in reward assignment, leading to more accurate learning.
- Compact Filtering: Filters out low-quality or incomplete trajectories, promoting deliberate and effective multi-step reasoning.
These algorithmic advances drive faster convergence and higher-quality behaviors, especially on complex software engineering problems.
Test-Time Scaling: Maximizing Results
Hybrid test-time scaling (TTS) sets DeepSWE-Preview apart. Rather than simply increasing the length of input or output, the model generates and evaluates multiple solution trajectories per task. Using both execution-based and execution-free verifiers, it selects the best candidate, boosting performance to 59% Pass@1, 12% higher than previous open-weight leaders.
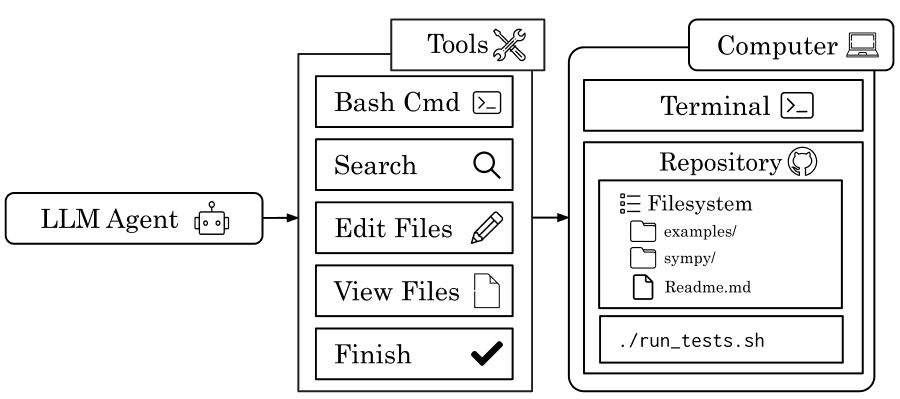
Image: together.ai Figure 4: Overview of SWE-Agents. LLM agents are equipped with standard IDE tools (e.g., Bash commands, file search, file viewer/editor) to interact with a simulated software-engineering environment comprising a terminal and a project filesystem.
Emergent Behaviors: Beyond Imitation
Notably, DeepSWE-Preview’s reinforcement learning (RL) training leads to sophisticated and unscripted behaviors that mirror the practices of seasoned engineers. The agent has been observed to anticipate edge cases and proactively run regression tests. It also dynamically adjusts its "thinking effort," allocating more resources to challenging steps like bug localization while streamlining routine tasks for greater efficiency.
Benchmark Results: Leading the Pack
On the SWE-Bench-Verified benchmark, DeepSWE-Preview stands out with:
- 42.2% Pass@1 (single solution scenario)
- 71.0% Pass@16 (across the top 16 solutions)
- 59% Pass@1 via hybrid TTS (best among multiple candidates)
These figures surpass prior open-source models such as Devstral-Small, OpenHands-LM, and Skywork-SWE, validating the RL-centric approach for autonomous coding agents.
Lessons and the Road Ahead
Experiments with traditional fine-tuning and alternative datasets showed RL-first, curriculum-based training with R2E-Gym as most effective. The team’s future goals include scaling to even larger models, handling longer contexts, and applying their methods to new agentic domains like web-based automation.
Takeaway: Open, RL-Driven, and Community-Focused
DeepSWE-Preview marks a leap forward for open-source software engineering automation. By sharing the full RL pipeline and tools, the project empowers the community to innovate further. The results underscore that RL-trained LLM agents can reliably tackle complex, real-world coding challenges, heralding a new era for autonomous development tools.
Source: DeepSWE: Training a Fully Open-sourced, State-of-the-Art Coding Agent by Scaling RL (Agentica & Together AI, 2025)


DeepSWE-Preview Sets a New Standard for Open-Source Coding Agents with Reinforcement Learning