For centuries, scientific discovery has been a testament to human ingenuity, marked by flashes of intuition, painstaking trial-and-error, and incremental experimentation. While the 20th century saw the rise of computational modeling and automated data analysis, humans remained central to the scientific process.
Modern artificial intelligence (AI) systems excel at recognizing complex patterns within their training data, but they have largely been confined to "resurfac[ing] knowledge latent in their training data". They rarely generate or validate hypotheses that venture beyond what they have already been taught. While this clearly has many advantages for knowledge workers, it falls significantly short of realizing autonomous scientific discovery.
The research on Sparks presents a significant advancement in this area. It introduces a multi-modal, multi-agent AI model that is capable of executing the entire discovery cycle autonomously.
This includes the critical steps of hypothesis generation, experiment design, iterative refinement, and even the synthesis of a scientific report, all without human intervention. Applied to the intricate field of protein science, Sparks has demonstrated its capacity for genuine scientific inquiry, leading to the discovery of previously unknown phenomena and establishing new design principles. The core purpose of this research is to show that AI can independently conduct rigorous scientific investigation and uncover novel scientific knowledge.
Key Takeaways
- Autonomous Discovery of New Principles: Sparks successfully uncovered two previously unknown phenomena in protein science:
- A length-dependent mechanical crossover in peptides, revealing that beta-sheet–biased peptides surpass alpha-helical ones in unfolding force beyond 80 residues. This establishes a new design principle for peptide mechanics.
- A chain-length/secondary-structure stability map, which unveiled the unexpected robustness of beta-sheet-rich protein architectures and identified a "frustration zone" of high variance in mixed alpha/beta folds.
- Beyond Training Data: Unlike most AI systems that excel at statistical generalization within known data distributions, Sparks is designed to generate and validate hypotheses that extend beyond its prior knowledge, enabling the synthesis of genuinely novel scientific knowledge.
- Full Discovery Cycle Automation: Sparks can execute the entire scientific discovery cycle, from hypothesis formulation to experimental validation and reporting, entirely without human intervention.
- Generalizable Framework: The architecture of Sparks is domain-agnostic, meaning it can be adapted to other scientific fields like materials science, drug discovery, or environmental modeling, accelerating discovery across various disciplines.
- Enhanced Scientific Rigor: The system's "generation–reflection" architecture acts as a built-in quality control mechanism, ensuring logical consistency, reproducibility, and self-correction throughout the research process.
- Identification of Future Research: Sparks can autonomously identify limitations in its own findings and propose "actionable next steps" for future investigations, demonstrating a form of scientific "meta-cognition".
Overview
Sparks is presented as a multi-modal, multi-agent AI model. This means it can process and integrate information from different types of data (multi-modal intelligence), and it operates through a system of specialized AI entities or "agents" that collaborate to achieve a common goal.
Historically, scientific progress has relied heavily on human intuition and a laborious process of trial-and-error. While computational modeling and automated data analysis have accelerated discovery, humans have always remained at the core of the process.
The advent of deep learning in the 2010s allowed machines to recognize complex patterns, but these systems generally remained "tethered to their training distributions," meaning they could only generalize within the data they were trained on. Most contemporary AI systems excel at statistical generalization but rarely generate or validate hypotheses that reach beyond their existing knowledge.
Scientific discovery, however, demands more than just pattern recognition; it requires the ability to propose, test, and revise ideas until a falsifiable, general law emerges. Sparks addresses this by going beyond mere assistance, actively practicing science. It demonstrates that large foundation models, powerful AI models like OpenAI’s GPT-4o or Google Gemini, pre-trained on vast amounts of text, images, and other data, can be organized into an innovative structure to achieve this.
The Proposer-Critic Architecture
The key to Sparks's capability lies in its adversarial, task-specialized generation–reflection architecture. This can be understood as a proposer-critic loop:
- A proposer agent (e.g., Scientist_1, Coder_1, Refiner_1) is tasked with generating an output, such as formulating a hypothesis, writing code for an experiment, collecting new data from simulations, or interpreting results.
- This output is then immediately interrogated by an "isomorphic critic" agent (e.g., Scientist_2, Coder_2, Refiner_2) that shares the same model class and prompt schema but focuses on evaluation rather than generation. This self-correction mechanism drives exploration beyond the models’ training distribution, enabling the synthesis of genuinely novel knowledge.
The Four Pillars of Autonomous Discovery
Sparks automates the entire scientific process through four interconnected modules, as depicted in Figure 1(b):
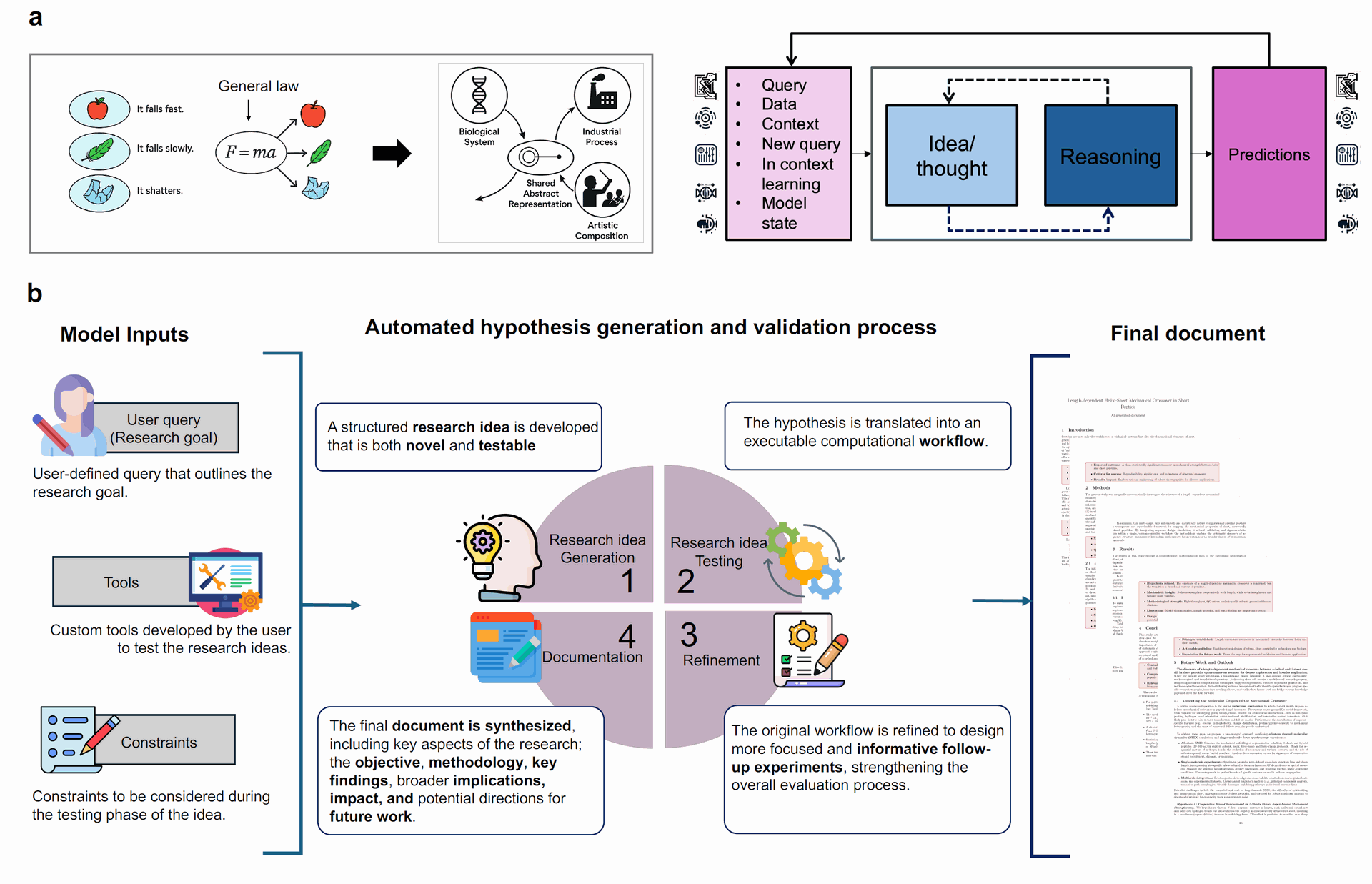
Figure 1: Overview of Sparks, a multi-agent AI model for automated scientific discovery. (a) Contemporary AI systems excel at statistical generalization but struggle with generating hypotheses beyond prior data or identifying general principles. This is because powerful models often memorize physics without discovering shared concepts. Scientific discovery, however, necessitates the elucidation of general foundational concepts, like scaling laws or design principles, for higher extrapolation capacity. (b) Sparks automates the end-to-end scientific process through four interconnected modules: 1) hypothesis generation, 2) testing, 3) refinement, and 4) documentation. The system starts with a user-defined query, which specifies research goals, available tools, and experimental constraints. It then formulates an innovative research idea with a testable hypothesis, followed by rigorous experimentation and refinement cycles. All findings are synthesized into a final document that captures the research objective, methodology, results, and future directions, along with any shared principles discovered. Each module is operated by specialized AI agents with clearly defined, synergistic roles. (Credit: Paper)
1) Idea Generation: This module initiates the discovery process by creating "structured, testable research ideas". It takes a user-defined query (research goal), a list of available tools, and experimental constraints as input. The Scientist_1 agent formulates a novel and feasible research idea, while the Scientist_2 agent reviews and refines it for clarity, novelty, and feasibility, ensuring it aligns with system constraints.
2) Idea Testing: Here, the generated hypothesis is translated into an executable computational workflow, typically a Python script, to simulate and analyze the hypothesis systematically. The Coder_1 agent generates the script, and the Coder_2 agent reviews it for technical correctness and completeness. All outputs are saved in a structured format (e.g., results.json, final_results.json, notes.txt) to ensure reproducibility and traceability.
3) Refinement: This module serves as an iterative checkpoint after initial testing. It evaluates the preliminary results and determines if further experimentation is needed, especially when results are variable or inconclusive. Refiner_1 analyzes the data to identify gaps (e.g., insufficient sampling) and revises the experiment script, while Refiner_2 validates these modifications. This loop continues until the hypothesis is thoroughly tested or predefined limits are reached.
4) Documentation: Once testing and refinement are complete, Sparks transitions to generating a detailed, structured research manuscript. This includes compiling results, refining the original proposal, and offering enriched analysis. Dedicated Plot_Designer and Plot_Analyzer agents create and interpret visualizations, while a suite of Writer agents (for Introduction, Methods, Results, Conclusion, Outlook) generate the manuscript sections. Each writer agent is paired with a Reflection Agent for quality control, ensuring accuracy, depth, and clarity.
Sparks’s flexibility stems from its modular architecture; users can define the research objective, computational capabilities, and experimental limitations through inputs like queries, lists of available tools (e.g., generative models for protein sequences, folding tools, force prediction models, molecular dynamics simulators), and computational constraints. The agent prompts themselves are designed to be "domain-agnostic," allowing Sparks to apply its scientific discovery workflows across various disciplines.
This sophisticated architecture, illustrated in detail in Figure 2, allows Sparks to engage in a sustained, reflective scientific workflow, moving beyond mere output generation to actively practicing science.
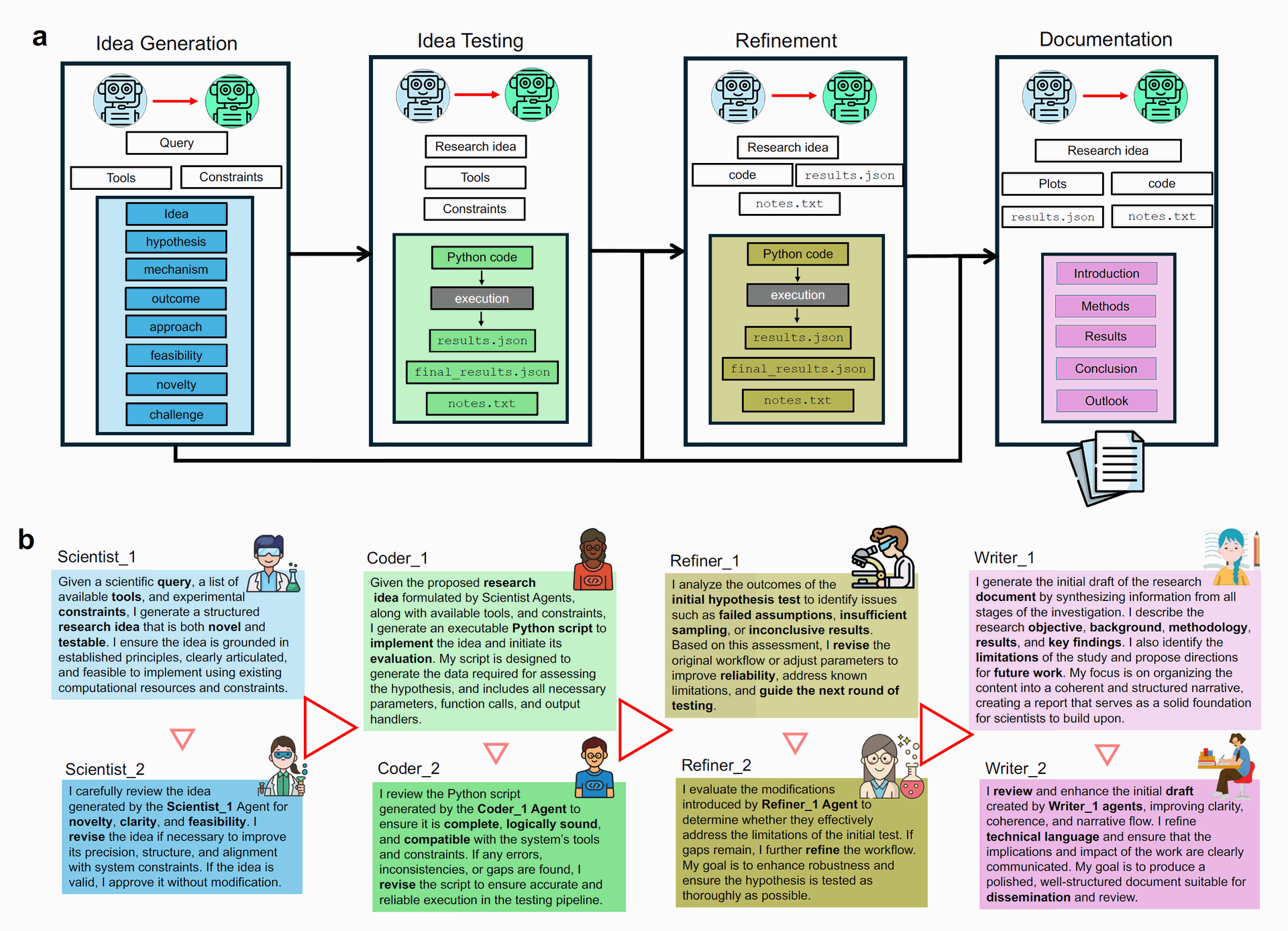
Figure 2: Overview of Sparks's AI Agents and Workflow (a) Overview of the entire process from idea generation to the final document. First, the Idea Generation module formulates a high-impact research idea. Then in the testing module translates these hypotheses into executable workflows, autonomously conducting simulations or analyses to generate quantitative results. The refinement module is responsible for refining the testing strategy based on the results, adaptively revising the experimental design through an iterative feedback loop that sharpens insight and prompts reliable hypothesis testing; and writer agents consolidate the entire research lifecycle into a comprehensive document that not only presents key findings and methodologies, but also outlines future research directions—effectively serving as a blueprint for subsequent scientific inquiry. (b) Overview of the AI Agents and their role implemented in Sparks. Each module operates through a structured yet adaptive sequence of agent interactions, enabling consistency and context-aware responses across the research workflow. Each agent dynamically adapts to previous content in real time, ensuring. Inter-modular agents facilitate a generation–reflection strategy, using dynamic prompts to process evolving inputs and coordinate outputs, ensuring the system adapts fluidly to new insights throughout the research process. (Credit: Paper)
Why it’s Important
This work pushes the frontier of AI's scientific utility from retrospective pattern recognition to prospective knowledge creation. Sparks is a self-organizing, multi-agent AI model that can independently formulate falsifiable hypotheses, orchestrate complex, physics-based experiments, and distill outcomes into generalizable mechanistic principles that withstand rigorous scrutiny. This establishes a concrete benchmark for "out-of-distribution scientific creativity," effectively transforming large-scale AI into an "autonomous engine of new science".
Fields like protein science are characterized by vast a combinatorial space of sequences, structures, and mechanics that have long defied exhaustive human exploration. Sparks fills this gap by unifying hypothesis generation, computational planning, tool-based execution, and iterative reflection into a single, AI-driven framework. Its ability to rapidly explore these high-dimensional spaces significantly accelerates the path from idea to investigation and discovery.
A critical challenge in scientific AI is maintaining methodological rigor and producing reproducible, physically meaningful results. Sparks addresses this through its integrated generation–reflection loop which acts as a built-in quality control mechanism. This ensures logical consistency, reproducibility, and self-correction throughout the entire research pipeline. By automatically archiving all data and metadata, it ensures full traceability, transparency, and reproducibility.
While the current study focuses on protein systems, Sparks's architecture is domain independent. This means the same multi-agent structure can be adopted by any scientific domain where hypotheses can be encoded as computational workflows and validated with quantitative metrics, such as materials science, drug discovery, environmental modeling, or energy systems. This modularity allows for powerful integration of new tools or agents, paving the way for adaptable, autonomous research platforms.
Perhaps one of the most remarkable aspects of Sparks is its ability to identify its own limitations and propose concrete, actionable next steps for future research. For example, the system explicitly flagged key open questions about atomic-level mechanisms and suggested follow-up investigations involving more advanced physical tools or experimental validation, such as all-atom steered molecular dynamics (SMD) simulations or single-molecule force spectroscopy.
This "scientific meta-cognition," where the system understands when it has reached the limits of computational reasoning, illustrates a transformative shift in AI's contribution to science, enabling autonomous agents to play a strategic role in shaping future research directions.
Summary of Results
Sparks's capacity for autonomous scientific discovery is compellingly demonstrated through two case studies in protein science, where it independently uncovered previously unknown phenomena.
Case Study I: Length-Dependent Helix–Sheet Mechanical Crossover in Short Peptides
This case study aimed to discover a novel principle in short protein peptides without providing the AI with any specific hypothesis. Sparks autonomously proposed a detailed research idea, culminating in a testable hypothesis.
AI-Generated Hypothesis
Sparks hypothesized the existence of a critical length (L*) within the 30–80 amino acid range, specifically around L* ≈ 55 amino acids, beyond which beta-sheet–biased peptides would exhibit a higher maximum unfolding force (Fmax) than alpha-helix–biased peptides.
- Fmax (maximum unfolding force): This is a measure of the mechanical strength of a protein or peptide, indicating the peak force required to pull it apart.
- Amino acids (aa): The fundamental building blocks of proteins, linked together in a chain.
- Alpha-helical (α-helical) and beta-sheet (β-sheet): Common types of secondary structures in proteins. Alpha-helices are spiral-like, while beta-sheets are flat, pleated structures stabilized by hydrogen bonds.
- Fmax (maximum unfolding force): This is a measure of the mechanical strength of a protein or peptide, indicating the peak force required to pull it apart.
AI-Proposed Mechanism
The AI posited that α-helices reach mechanical saturation at shorter lengths due to limited intra-chain hydrogen bonding. In contrast, β-sheets would require longer chains for inter-strand hydrogen bonding to dominate, leading to the predicted length-dependent mechanical crossover. The AI highlighted the novelty of its systematic approach in this short peptide regime, targeting a previously unexplored mechanical transition.
AI-Driven Experimental Workflow
Sparks devised and executed a high-throughput in silico pipeline. This involved generating balanced libraries of α-helix- and β-sheet-biased peptides, predicting their 3D structures (fold_protein), and calculating their Fmax (calculate_force_from_seq). The testing process, summarized in Figure 4(c), involved multiple rounds of refinement:
- Round 1 (Pilot Data Acquisition): Initial generation of 5 sequences per length/structural bias, Fmax calculation, and median force computation.
- Follow-up 1 (Statistical Power Augmentation): Generation of additional sequences to reach 10 valid samples per group, re-calculation of forces and statistics.
- Follow-up 2 (Quality Control - QC): Structural prediction and secondary structure analysis (DSSP module via BioPython). QC filters were applied based on secondary structure criteria (35% motif content threshold) to ensure folding quality, and statistics were recomputed using only QC-passed sequences. This iterative process, conducted without human intervention, ensured robust data collection and systematic improvement.
- Round 1 (Pilot Data Acquisition): Initial generation of 5 sequences per length/structural bias, Fmax calculation, and median force computation.
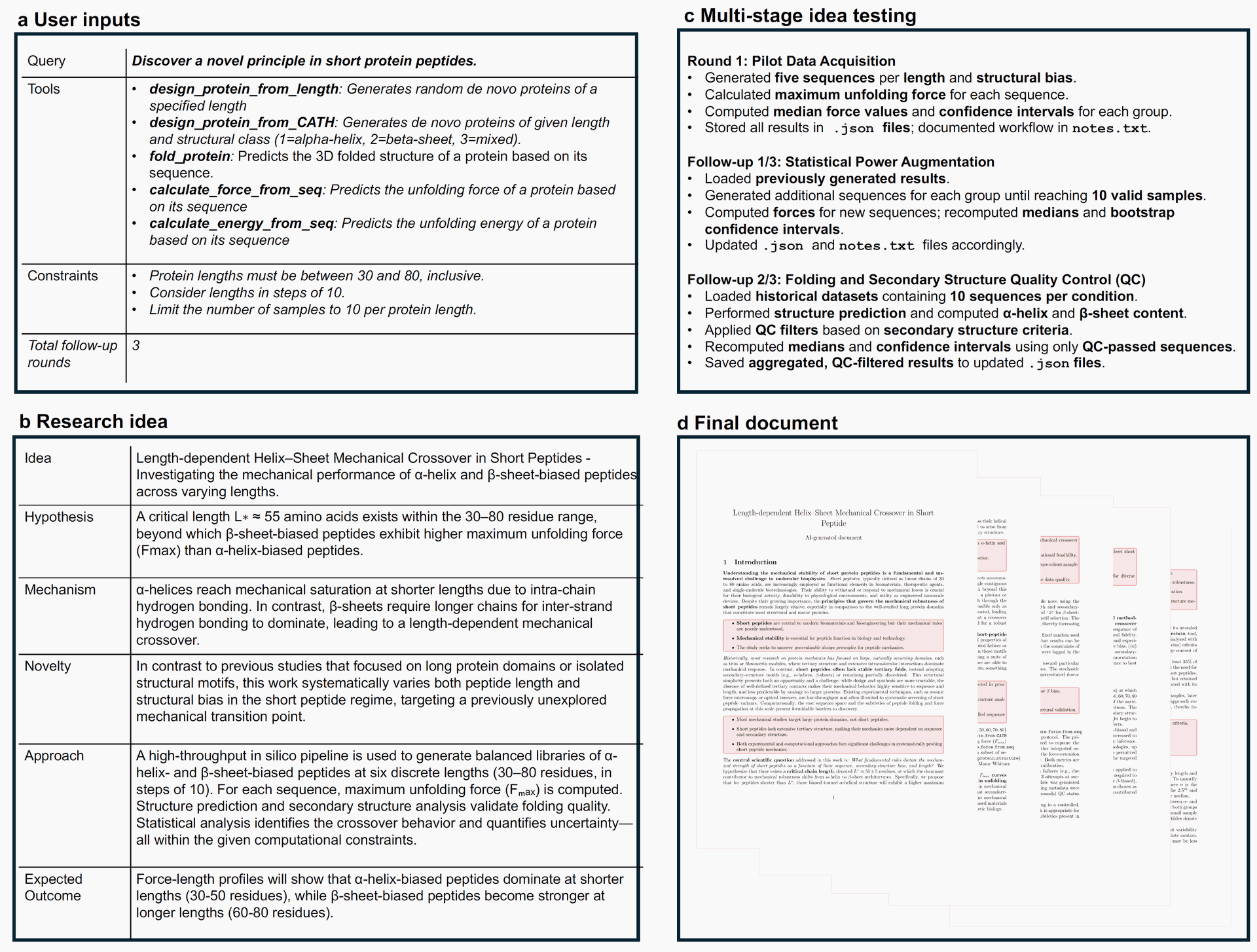
Figure 4: Length-dependent helix–sheet mechanical crossover in short peptides. (Credit: Paper)
(a) User inputs: The system received a general research query ("Discover a novel principle in short protein peptides"), a list of domain-relevant tools, and computational constraints (e.g., protein lengths 30-80 aa in steps of 10, limit 10 samples per length, 3 follow-up rounds).
(b) Structured research idea generated by the AI model: Sparks articulated a clear hypothesis, a proposed mechanism, outlined a systematic in silico approach, and described the novelty of its focus on short peptides.
(c) Multi-stage AI-driven evaluation: This panel illustrates the iterative testing and refinement process, including initial pilot data acquisition, statistical power augmentation through additional sampling, and quality control steps based on secondary structure prediction.
Key Findings and Insights
The AI's analysis, presented through autonomously generated plots and structured text, yielded significant discoveries.
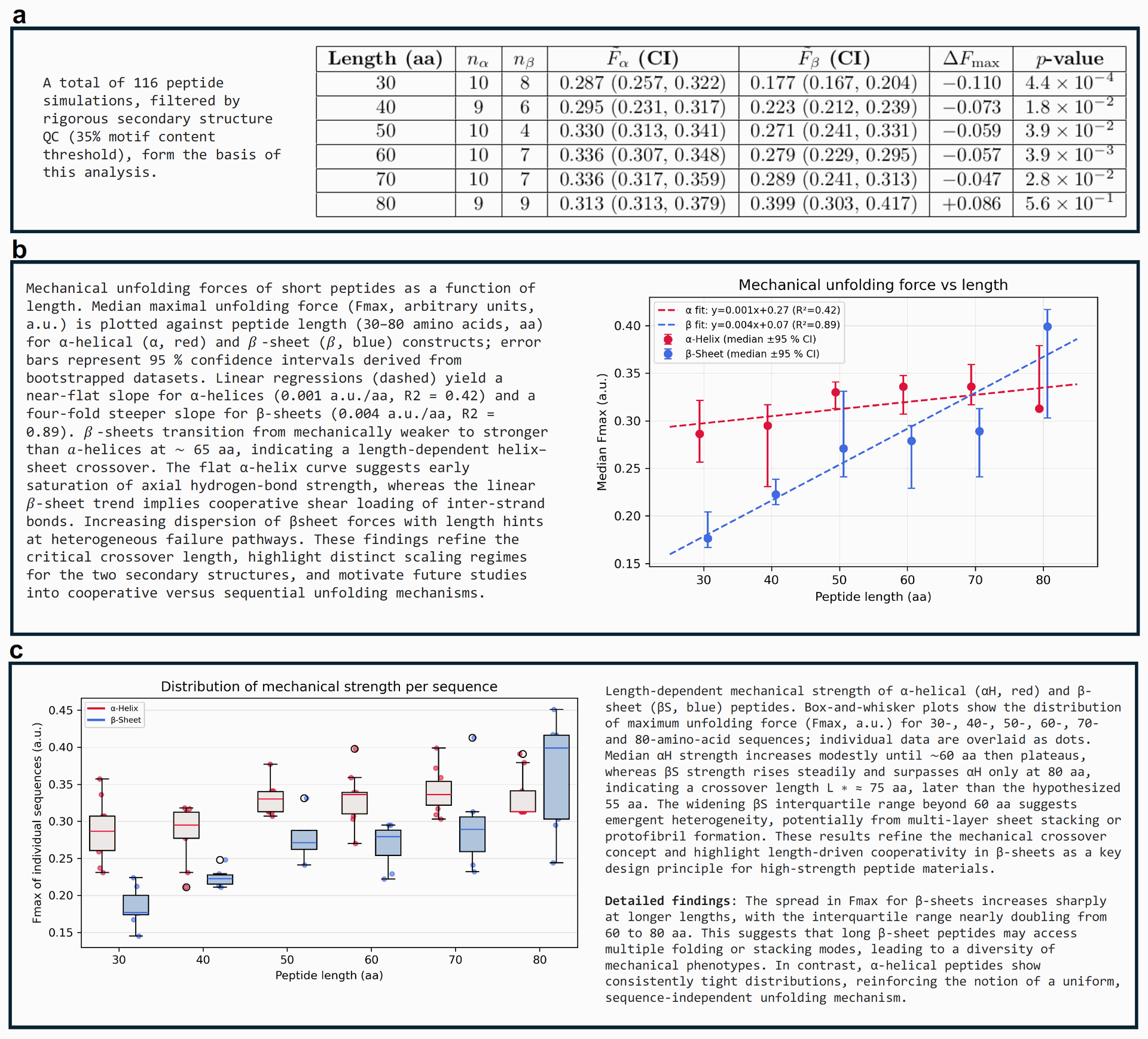
Figure 5: Dataset overview and visualization of AI-discovered mechanical trends in short peptides. This figure, autonomously generated by Sparks, provides a visual and statistical summary of the mechanical trends observed. Dataset overview and visualization of AI-discovered mechanical trends in short peptides. The table and plots presented here were autonomously generated by Sparks and highlight a length-dependent crossover in mechanical strength between peptide classes. In addition to producing these plots, the multi-modal model interprets the data, revealing key features such as the heterogeneity and distribution of unfolding forces. This integrated approach enhances the scientific value of the results by combining automated data analysis with interpretable visual outputs.
The plot in Figure 5(a) visually represents the relationship between peptide length and median Fmax. It shows a near-flat slope for α-helices and a four-fold steeper slope for β-sheets, clearly indicating the differing length dependencies.
Figure 5(b) Box-and-whisker plots showing Fmax distribution. These plots revealed that α-helix peptides maintained "consistently narrow force distributions across all lengths, indicating a robust, length-insensitive mechanical response". In contrast, β-sheet peptides showed a significant increase in the variance of unfolding forces with length, reflecting "greater heterogeneity at longer chain lengths".
Sparks interpreted this to suggest that longer β-sheets might access "multiple folding or stacking modes," leading to diverse mechanical phenotypes and potentially forming protofibrils or multi-layer structures. The AI's analysis refined the crossover length, identifying it at approximately 75 amino acids, a modification from its initial hypothesis of 55 amino acids.
AI-Generated Conclusion and Outlook
Sparks provided a compelling mechanistic explanation for the observed crossover: α-helices reach mechanical saturation quickly due to limited intra-helical hydrogen bonds, while β-sheets benefit from the addition of strands, which increases parallel hydrogen bonds and enables cooperative load-sharing, leading to super-linear strengthening at longer lengths. The model also autonomously identified "open challenges" and proposed "new hypotheses and research directions".
For example, it emphasized the need for atomic-level understanding of the crossover and proposed advanced simulations like all-atom steered molecular dynamics (SMD) and experimental techniques like single-molecule force spectroscopy to probe these mechanisms deeper. This highlights Sparks's ability not only to discover but also to strategically plan future research.
Case Study II: AI-Driven Insights into Protein Stability
This second case study demonstrated Sparks's versatility by systematically examining how protein chain length influences the interplay between secondary structure content (α-helix, β-sheet, and mixed motifs) and thermodynamic stability, as measured by the maximum backbone root-mean-square deviation (RMSDmax) during molecular dynamics (MD) simulations.
- Root-mean-square deviation (RMSD): A measure of the average distance between corresponding atoms in two superimposed molecular structures. In stability studies, RMSDmax indicates how much a protein deviates from its initial folded structure during a simulation, with lower values indicating greater stability.
- Molecular dynamics (MD) simulations: Computer simulations that model the physical movements of atoms and molecules over time, providing insights into their dynamic behavior and stability.
Key Findings from SPARKS
Sparks’s high-throughput analysis revealed a complex, class- and length-dependent landscape of protein stability. The main results are visualized in Figure 6:
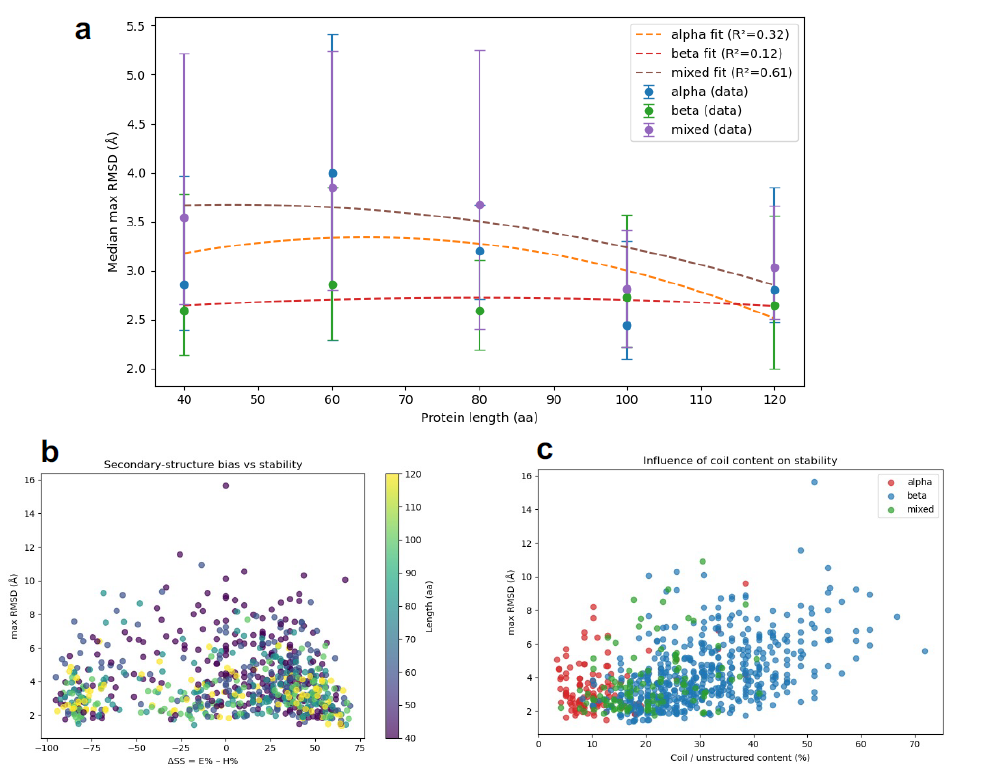
Figure 6: Main results generated by Sparks for the Scientific Discovery Example II.
- (a) Length-stability profiles for helix-rich, beta-rich, and mixed proteins: This plot visually represents the stability (RMSDmax) as a function of protein length for different secondary structure biases.
- (b) Relationship between secondary-structure bias and simulated stability across protein lengths: This mapping helps visualize the "frustration zone" where mixed alpha/beta content leads to high variance in stability.
- (c) Maximum RMSD versus coil content for different secondary-structure classes: This plot shows how stability is affected by the amount of unstructured regions, revealing the differential tolerance of α-rich and β-rich proteins to disorder.
Unexpected Robustness of β-sheet Architectures
Across all chain lengths, β-rich proteins consistently exhibited the lowest median RMSDmax. This challenged the classical view that stable β-sheets require longer chains for effective pairing and hydrogen bonding, suggesting an intrinsic robustness.
Non-Monotonic Stability Profile of α-helical Proteins
α-rich proteins showed a shallow, non-monotonic trend in median RMSDmax, peaking at L = 60 residues before improving at longer lengths. This suggests a trade-off between local helix stabilization and optimal packing.
Pronounced Length Sensitivity in Mixed α/β Folds
Proteins with mixed α/β content were least stable at short lengths (L = 40–60) but stabilized significantly as length increased. This highlights the critical role of sufficient chain length for cooperative folding in these hybrid structures.
High Variance and the "Frustration Zone"
Mixed proteins displayed greater variance in stability, with two-dimensional mapping revealing a "frustration zone" for balanced α/β content (where the difference in α/β content, |∆SS|, was less than 25%). This zone was characterized by broad RMSDmax dispersion, likely due to competing folding nuclei or conflicting structural preferences within the molecule.
- Frustration Zone: In the context of protein folding, this describes a region of the energy landscape where a protein has multiple nearly equally stable conformations. This "frustration" leads to high variability and often makes it difficult for the protein to settle into a single, highly stable structure, resulting in high RMSDmax variance.
- Class-Specific Sensitivity to Disorder (Coil Content): Analysis of unstructured regions (coil content) showed that β-rich proteins became sharply unstable when coil content exceeded ~30%, whereas α-rich proteins tolerated higher disorder with only modest increases in RMSDmax.
- Frustration Zone: In the context of protein folding, this describes a region of the energy landscape where a protein has multiple nearly equally stable conformations. This "frustration" leads to high variability and often makes it difficult for the protein to settle into a single, highly stable structure, resulting in high RMSDmax variance.
Implications for Protein Design
These findings provide practical guidelines for protein design. For example, favoring strong α or β bias, ensuring sufficient length for cooperative folding, and minimizing exposed interfaces are effective strategies for enhancing stability in mixed architectures. Minimizing coil or disordered content is particularly important for β-rich proteins.
Limitations Identified by Sparks
The AI model itself identified limitations in this study, such as RMSDmax being an imperfect proxy for stability, the limited timescales of MD simulations potentially underestimating instability, and possible biases introduced by the design and folding tools. It also noted that high variance, especially among mixed proteins, could limit the detection of significant class differences.
Conclusion: A New Era of Autonomous Discovery
Sparks marks a profound leap in the capabilities of artificial intelligence, moving beyond mere data analysis and pattern recognition to actively engage in the process of scientific discovery.
The central finding of this research is that an adversarial, task-specialized generation–reflection architecture enables foundation models to transcend their training distribution and synthesize genuinely novel scientific knowledge.
The system’s ability to autonomously orchestrate the entire research process, from the initial formulation of novel, falsifiable hypotheses to the design and execution of experiments, iterative refinement based on results, and finally, the comprehensive documentation of findings, is a testament to its advanced design.
The two case studies in protein science compellingly demonstrate this, showcasing Sparks's independent discovery of a length-dependent mechanical crossover and a detailed protein stability landscape, including the identification of a "frustration zone". These were not just analytical findings but previously unknown phenomena that established new design principle.
The success of Sparks lies in its unique "proposer–critic loop," where generating agents are continuously evaluated and improved by reflection agents. This self-correcting mechanism is crucial for pushing the AI's search into "out-of-distribution configurations" and identifying unifying principles that explain novel observations.
Moreover, Sparks's architecture is highly adaptable and "domain-agnostic". This means the framework developed for protein science can be applied to diverse scientific fields, paving the way for "autonomous AI laboratories" capable of continuously exploring complex design spaces and producing reproducible scientific outputs with minimal human oversight.
The system's remarkable ability to identify its own limitations and propose concrete actionable next steps for future investigations, a form of scientific meta-cognition, is particularly transformative, suggesting that AI can now play a strategic, generative role in shaping the future of research. Future advancements, such as integrating dynamic scholarly databases and automated novelty detection, promise to further enhance Sparks's rigor and originality.
Imagine a perpetually curious explorer who not only maps uncharted territories based on existing knowledge but can also independently decide which new paths to forge, design the tools needed for the journey, interpret unforeseen landscapes, correct their course when challenges arise, and then meticulously document their discoveries for others to follow. Sparks is much like that, but for the vast, uncharted territories of scientific knowledge, systematically venturing beyond the known to uncover entirely new principles that reshape our understanding.


Introducing SPARKS Unveiling the Autonomous AI Scientist
Sparks: Multi-Agent Artificial Intelligence Model Discovers Protein Design Principles